Individual Project (iP):
Team Project (tP):
Week 2 [Fri, Aug 14th] - Topics
Given below are some topics relevant to the individual project (iP) tasks due this week. These are topics you have learned in TIC2002 (as indicated by icons with the prefix), given here for your reference only. You are recommended to refresh your knowledge about them as they will be tested in the weekly quiz.
Detailed Table of Contents
- [W2.1] Java: Intro
- [W2.2] Java: HelloWorld
- [W2.3] Java: Data Types
- [W2.4] Java: Control Flow
- [W2.5] OOP: Classes and Objects
- [W2.6] Java: Objects
- [W2.7] Java: Classes
- [W2.8] RCS: Init, Commit
-
[W2.8a] Project Management → Revision Control → What :
-
[W2.8b] Project Management → Revision Control → Repositories :
-
[W2.8c] Tools → Git and GitHub →
init: Getting started : -
[W2.8d] Project Management → Revision Control → Saving history :
-
[W2.8e] Tools → Git and GitHub →
commit: Saving changes to history : -
[W2.8f] Tools → Git and GitHub → Omitting files from revision control :
- [W2.9] RCS: Remote Repos
- [W2.10] RCS: Using History
-
[W2.10a] Project Management → Revision Control → Using history :
-
[W2.10b] Tools → Git and GitHub →
tag: Naming commits : -
[W2.10c] Tools → Git and GitHub →
diff: Comparing revisions : -
[W2.10d] Tools → Git and GitHub →
checkout: Retrieving a specific revision : -
[W2.10e] Tools → Git and GitHub →
stash: Shelving changes temporarily
- [W2.11] IDEs: Basic Features
C++ to Java → About this chapter
This book chapter assumes you are familiar with basic C++ programming. It provides a crash course to help you migrate from C++ to Java.
This chapter borrows heavily from the excellent book ThinkJava by Allen Downey and Chris Mayfield. As required by the terms of reuse of that book, this chapter is released under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License and not under the MIT license as the rest of this book.
Some conventions used in this chapter:
icon marks the description of an aspect of Java that works mostly similar to C++
icon marks the description of an aspect of Java that is distinctly different from C++
Other resources used:
- C++ and Java Syntax Differences Cheat Sheet by Alex Allain
- Java Tutorial provided by Oracle. Extracts from this resource are marked as -- Java Tutorial
C++ to Java → The Java World → What is Java?
Can explain what Java is
Java was conceived by James Gosling and his team at Sun Microsystems in 1991.
Java is directly related to both C and C++. Java inherits its syntax from C. Its object model is adapted from C++. --Java: A Beginner’s Guide, by Oracle
Fun fact: The language was initially called Oak after an oak tree that stood outside Gosling's office. Later the project went by the name Green and was finally renamed Java, from Java coffee. --Wikipedia
Oracle became the owner of Java in 2010, when it acquired Sun Microsystems.
Java has remained the most popular language in the world for several years now (as at July 2018), according to the TIOBE index.
C++ to Java → The Java World → How Java works
Can explain how Java works at a higher-level
Java is both generates machine code from source code before executing the programcompiled and the interpreter executes the program directly, one statement at a timeinterpreted. Instead of translating programs directly into machine language, the Java compiler generates byte code. Byte code is portable, so it is possible to compile a Java program on one machine, transfer the byte code to another machine, and run the byte code on the other machine. That’s why Java is considered a platform independent technology, aka WORA (Write Once Run Anywhere). The interpreter that runs byte code is called a “Java Virtual Machine” (JVM).
Java technology is both a programming language and a platform. The Java programming language is a high-level object-oriented language that has a particular syntax and style. A Java platform is a particular environment in which Java programming language applications run. --Oracle
C++ to Java → The Java World → Java editions
Can explain Java editions
According to the Official Java documentation, there are four platforms of the Java programming language:
-
Java Platform, Standard Edition (Java SE): Contains the core functionality of the Java programming language.
-
Java Platform, Enterprise Edition (Java EE): For developing and running large-scale enterprise applications. Built on top of Java SE.
-
Java Platform, Micro Edition (Java ME): For Java programming language applications meant for small devices, like mobile phones. A subset of Java SE.
-
JavaFX: For creating applications with graphical user interfaces. Can work with the other three above.
This book chapter uses the Java SE edition unless stated otherwise.
C++ to Java → Getting Started → Installation
Can install Java
To run Java programs, you only need to have a recent version of the Java Runtime Environment (JRE) installed in your device.
If you want to develop applications for Java, download and install a recent version of the Java Development Kit (JDK), which includes the JRE as well as additional resources needed to develop Java applications.
C++ to Java → Getting Started → HelloWorld
Can explain the Java HelloWorld program
In Java, the HelloWorld program looks like this:
public class HelloWorld {
public static void main(String[] args) {
// generate some simple output
System.out.println("Hello, World!");
}
}
For reference, the equivalent C++ code is given below:
#include <iostream>
using namespace std;
int main() {
// generate some simple output
cout << "Hello, World!";
return 0;
}
This HelloWorld Java program defines one method named main: public static void main(String[] args)
System.out.println() displays a given text on the screen.
Some similarities:
- Java programs consists of statements, grouped A method is a named sequence of statementsmethods, which are then grouped into classes.
- Java is “case-sensitive”, which means
SYSTEMis different fromSystem. publicis an access modifier that indicates the method is accessible from outside this class. Similarly,privateaccess modifier indicates that a method/attribute is not accessible outside the class.staticindicates this method is defined as a class-level member. Do not worry if you don’t know what that means. It will be explained later.voidindicates that the method does not return anything.- The name and format of the
mainmethod is special as it is the method that Java executes when you run a Java program. - A class is a collection of methods. This program defines a class named
HelloWorld. - Java uses squiggly braces (
{and}) to group things together. - The line starting with
//is a comment. You can use//for single line comments and/* ... */for multi-line comments in Java code.
A statement is a line of code that performs a basic operation. In the HelloWorld program, this line is a print statement that displays a message on the screen:
System.out.println("Hello, World!");
Some differences:
- Java use the term method instead of function. In particular, Java doesn’t have stand-alone functions. Every method should belong to a class. The
mainmethod will not work unless it is inside theHelloWorldclass. - A Java class definition does not end with a semicolon, but most Java statements do.
- In most cases (i.e., there are exceptions), the name of the class has to match the name of the file it is in, so this class has to be in a file named
HelloWorld.java. - There is no need for the HelloWorld code to have something like
#include <iostream>. The library files needed by the HelloWorld code is available by default without having to "include" them explicitly. - There is no need to
return 0at the end of the main method to indicate the execution was successful. It is considered as a successful execution unless an error is signalled specifically.
C++ to Java → Getting Started → Compiling a program
Can compile a simple Java program
To compile the HelloWorld program, open a command console, navigate to the folder containing the file, and run the following command.
javac HelloWorld.java
If the compilation is successful, you should see a file HelloWorld.class. That file contains the byte code for your program. If the compilation is unsuccessful, you will be notified of the compile-time errors.
Compile-time errors (aka compile errors) occur when you violate the syntax rules of the Java language. For example, parentheses and braces have to come in matching pairs.
Error messages from the compiler usually indicate where in the program the error occurred, and sometimes they can tell you exactly what the error is.
Notes:
javacis the java compiler that you get when you install the JDK.- For the above command to work, your console program should be able to find the javac executable (e.g., In Windows, the location of the
javac.exeshould be in thePATHsystem variable).
This page shows how to set PATH in different OS'es.
C++ to Java → Getting Started → Running a program
Can run a simple Java program
To run the HelloWorld program, in a command console, run the following command from the folder containing HelloWorld.class file.
java HelloWorld
Notes:
javain the command above refers to the Java interpreter installed in your computer.- Similar to
javac, your console should be able to find the java executable.
When you run a Java program, you can encounter a so-called because it does not appear until after the program has started runningrun-time error. These errors are also called "exceptions" because they usually indicate that something exceptional (and bad) has happened. When a run-time error occurs, the interpreter displays an error message that explains what happened and where.
For example, modify the HelloWorld code to include the following line, compile it again, and run it.
System.out.println(5/0);
You should get a message like this:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at Hello.main(Hello.java:5)
Integrated Development Environments (IDEs) can automate the intermediate step of compiling. They usually have a Run button which compiles the code first and then runs it.
Example IDEs:
- Intellij IDEA
- Eclipse
- NetBeans
Exercises
[Exercise] Run HelloWorld
- Install Java in your computer, if you haven't done so already.
- Write, compile and run a small Java program (e.g., a HelloWorld program) in your computer. You can use any code editor to write the program but use the command prompt to compile and run the program.
- Modify the code to print something else, save, compile, and run the program again.
C++ to Java → Data Types → Primitive data types
Can use primitive data types
Java has a number of primitive data types, as given below:
byte: an integer in the range -128 to 127 (inclusive).short: an integer in the range -32,768 to 32,767 (inclusive).int: an integer in the range -231 to 231-1.long: An integer in the range -263 to 263-1.float: a single-precision 32-bit IEEE 754 floating point. This data type should never be used for precise values, such as currency. For that, you will need to use the java.math.BigDecimal class instead.double: a double-precision 64-bit IEEE 754 floating point. For decimal values, this data type is generally the default choice. This data type should never be used for precise values, such as currency.boolean: has only two possible values:trueandfalse.char: The char data type is a single 16-bit Unicode character. It has a minimum value of'\u0000'(or0) and a maximum value of'\uffff'(or65,535inclusive).
The String type (a peek)
Java has a built-in type called String to represent strings. While String is not a primitive type, strings are used often. String values are demarcated by enclosing in a pair of double quotes (e.g., "Hello"). You can use the + operator to concatenate strings (e.g., "Hello " + "!").
You’ll learn more about strings in a later section.
C++ to Java → Data Types → Variables
Can use variables
Java is a statically-typed language in that variables have a fixed type. Here are some examples of declaring variables and assigning values to them.
int x;
x = 5;
int hour = 11;
boolean isCorrect = true;
char capitalC = 'C';
byte b = 100;
short s = 10000;
int i = 100000;
You can use any name starting with a letter, underscore, or $ as a variable name but you cannot use Java keywords as variables names.
You can display the value of a variable using System.out.print or System.out.println (the latter goes to the next line after printing). To output multiple values on the same line, it’s common to use several print statements followed by println at the end.
int hour = 11;
int minute = 59;
System.out.print("The current time is ");
System.out.print(hour);
System.out.print(":");
System.out.print(minute);
System.out.println("."); //use println here to complete the line
System.out.println("done");
The current time is 11:59.
done
Use the keyword final to indicate that the variable value, once assigned, should not be allowed to change later i.e., act like a ‘constant’. By convention, names for constants are all uppercase, with the underscore character (_) between words.
final double CM_PER_INCH = 2.54;
C++ to Java → Data Types → Operators
Can use operators
Java supports the usual arithmetic operators, given below.
| Operator | Description | Examples |
|---|---|---|
+ |
Additive operator | 2 + 3 5 |
- |
Subtraction operator | 4 - 1 3 |
* |
Multiplication operator | 2 * 3 6 |
/ |
Division operator | 5 / 2 2 but 5.0 / 2 2.5 |
% |
Remainder operator | 5 % 2 1 |
The following program uses some operators as part of an expression hour * 60 + minute:
int hour = 11;
int minute = 59;
System.out.print("Number of minutes since midnight: ");
System.out.println(hour * 60 + minute);
Number of minutes since midnight: 719
When an expression has multiple operators, normal operator precedence rules apply. Furthermore, you can use parentheses to specify a precise precedence.
Examples:
4 * 5 - 119(*has higher precedence than-)4 * (5 - 1)16(parentheses()have higher precedence than*)
Java does not allow changing the meaning of operatorsoperator overloading.
The unary operators require only one operand; they perform various operations such as incrementing/decrementing a value by one, negating an expression, or inverting the value of a boolean.-- Java Tutorial
| Operator | Description -- Java Tutorial | example |
|---|---|---|
+ |
Unary plus operator; indicates positive value (numbers are positive without this, however) |
x = 5; y = +x y is 5 |
- |
Unary minus operator; negates an expression | x = 5; y = -x y is -5 |
++ |
Increment operator; increments a value by 1 | i = 5; i++ i is 6 |
-- |
Decrement operator; decrements a value by 1 | i = 5; i-- i is 4 |
! |
Logical complement operator; inverts the value of a boolean | foo = true; bar = !foo bar is false |
Relational operators are used to check conditions like whether two values are equal, or whether one is greater than the other. The following expressions show how they are used:
| Operator | Description | example true |
example false |
|---|---|---|---|
x == y |
x is equal to y |
5 == 5 |
5 == 6 |
x != y |
x is not equal to y |
5 != 6 |
5 != 5 |
x > y |
x is greater than y |
7 > 6 |
5 > 6 |
x < y |
x is less than y |
5 < 6 |
7 < 6 |
x >= y |
x is greater than or equal to y |
5 >= 5 |
4 >= 5 |
x <= y |
x is less than or equal to y |
4 <= 5 |
6 <= 5 |
The result of a relational operator is a boolean value.
Java has three conditional operators that are used to operate on boolean values.
| Operator | Description | example true |
example false |
|---|---|---|---|
&& |
and | true && true true |
true && false false |
|| |
or | true || false true |
false || false false |
! |
not | not false |
not true |
Resources
- Oracle's tutorial on operators: part 1, part 2
- A tutorial on operators by tutorialspoint.com
C++ to Java → Data Types → Arrays
Can use arrays
Arrays are indicated using square brackets ([]). To create the array itself, you have to use the new operator. Here are some example array declarations:
int[] counts;
counts = new int[4]; // create an int array of size 4
int size = 5;
double[] values;
values = new double[size]; //use a variable for the size
double[] prices = new double[size]; // declare and create at the same time
Alternatively, you can use the shortcut syntax to create and initialize an array:int[] values = {1, 2, 3, 4, 5, 6};
int[] anArray = {
100, 200, 300,
400, 500, 600,
700, 800, 900, 1000
};-- Java Tutorial
The [] operator selects elements from an array. Array elements i.e., the index of the first element is 0, not 1indices start from 0.
int[] counts = new int[4];
System.out.println("The first element is " + counts[0]);
counts[0] = 7; // set the element at index 0 to be 7
counts[1] = counts[0] * 2;
counts[2]++; // increment value at index 2
A Java array is aware of its size. A Java array prevents a programmer from indexing the array out of bounds. If the index is negative or not present in the array, the result is an error named ArrayIndexOutOfBoundsException.
int[] scores = new int[4];
System.out.println(scores.length) // prints 4
scores[5] = 0; // causes an exception
4
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 5
at Main.main(Main.java:6)
It is also possible to create arrays of more than one dimension:
String[][] names = {
{"Mr. ", "Mrs. ", "Ms. "},
{"Smith", "Jones"}
};
System.out.println(names[0][0] + names[1][0]); // Mr. Smith
System.out.println(names[0][2] + names[1][1]); // Ms. Jones-- Java Tutorial
Passing arguments to a program
The args parameter of the main method is an array of Strings containing command line arguments supplied (if any) when running the program.
public class Foo{
public static void main(String[] args) {
System.out.println(args[0]);
}
}
You can run this program (after compiling it first) from the command line by typing:
java Foo abc
abc
Resources
Exercises
[Key Exercise] Compare names
Write a Java program that takes two command line arguments and prints true or false to indicate if the two arguments have the same value. Follow the sample output given below.
class Main {
public static void main(String[] args) {
// add your code here
}
}
java Main adam eve
Words given: adam, eve
They are the same: false
java Main eve eve
Words given: eve, eve
They are the same: true
Use the following technique to compare two Strings(i.e., don't use ==). Reason: to be covered in a later topic.
String x = "foo";
boolean isSame = x.equals("bar") // false
isSame = x.equals("foo") // true
- The two command line arguments can be accessed inside the
mainmethod usingargs[0]andargs[1]. - When using multiple operators in the same expression, you might need to use parentheses to specify operator precedence. e.g.,
"foo" + x == yvs"foo" + (x == y)
partial solution
class Main {
public static void main(String[] args) {
String first = args[0];
String second = args[1];
System.out.println("Words given: " + first + ", " + second);
// ...
}
}
C++ to Java → Control Flow → Branching
Can use branching
if-else statements
Java supports the usual forms of if statements:
if (x > 0) {
System.out.println("x is positive");
}
if (x % 2 == 0) {
System.out.println("x is even");
} else {
System.out.println("x is odd");
}
if (x > 0) {
System.out.println("x is positive");
} else if (x < 0) {
System.out.println("x is negative");
} else {
System.out.println("x is zero");
}
if (x == 0) {
System.out.println("x is zero");
} else {
if (x > 0) {
System.out.println("x is positive");
} else {
System.out.println("x is negative");
}
}
The braces are optional (but recommended) for branches that have only one statement. So we could have written the previous example this way ( Bad):
if (x % 2 == 0)
System.out.println("x is even");
else
System.out.println("x is odd");
switch statements
The switch statement can have a number of possible execution paths. A switch works with the byte, short, char, and int primitive data types. It also works with enums, String.
Here is an example (adapted from -- Java Tutorial):
public class SwitchDemo {
public static void main(String[] args) {
int month = 8;
String monthString;
switch (month) {
case 1: monthString = "January";
break;
case 2: monthString = "February";
break;
case 3: monthString = "March";
break;
case 4: monthString = "April";
break;
case 5: monthString = "May";
break;
case 6: monthString = "June";
break;
case 7: monthString = "July";
break;
case 8: monthString = "August";
break;
case 9: monthString = "September";
break;
case 10: monthString = "October";
break;
case 11: monthString = "November";
break;
case 12: monthString = "December";
break;
default: monthString = "Invalid month";
break;
}
System.out.println(monthString);
}
}
August
Exercises
Greeter
Write a Java program that takes several command line arguments that describe a person or a family | and prints out a greeting. The parameters can be one of two formats.
| arguments format | explanation | expected output |
|---|---|---|
NAME GENDER |
Indicates a single person. GENDER can be M or F |
Smith M Dear Mr. SmithLee F Dear Mdm. Lee |
NAME MULTIPLE_GENDERS |
Indicates a family. | Tan M M F Dear Tan family |
Follow the sample output given below.
java Greeter Smith M Dear Mr. Smith
java Greeter Lee F Dear Mdm. Lee
java Greeter Tan M M F Dear Tan family
You can assume that the input is always in the correct format i.e., no need to handle invalid input cases.
Partial solution:
public class Greeter {
public static void main(String[] args) {
String first = args[0];
String second = args[1];
if (args.length == 2) {
if (second.equals("M")) {
// ...
}
} else {
// ...
}
}
}
[Key Exercise] Grade Helper
Write a Java program that takes a letter grade e.g., A+ as a command line argument and prints the CAP value for that grade.
Use a switch statement in your code.
| A+ | A | A- | B+ | B | B- | C | Else |
|---|---|---|---|---|---|---|---|
| 5.0 | 5.0 | 4.5 | 4.0 | 3.5 | 3.0 | 2.5 | 0 |
Follow the sample output given below.
java GradeHelper B CAP for grade B is 3.5
You can assume that the input is always in the correct format i.e., no need to handle invalid input cases.
Partial solution:
public class GradeHelper {
public static void main(String[] args) {
String grade = args[0];
double cutoff = 0;
switch (grade) {
case "A+":
// ...
}
System.out.println("CAP for grade " + grade + " is " + cutoff);
}
}
C++ to Java → Control Flow → Methods
Can use methods
Defining methods
Here’s an example of adding more methods to a class:
public class PrintTwice {
public static void printTwice(String s) {
System.out.println(s);
System.out.println(s);
}
public static void main(String[] args) {
String sentence = “Polly likes crackers”
printTwice(sentence);
}
}
Polly likes crackers
Polly likes crackers
By convention, method names should be named in the camelCase format.
CamelCase is named after the "humps" of its capital letters, similar to the humps of a Bactrian camel. Camel case (stylized as
camelCase) is the practice of writing compound words or phrases such that each word or abbreviation in the middle of the phrase begins with a capital letter, with no intervening spaces or punctuation.-- adapted from Wikipedia
e.g., createEmptyList, listOfIntegers, htmlText, dvdPlayer. This book defines camelCase style as requiring the first letter to be lower case. If the first letter is upper case instead e.g., CreateEmptyList, it is called UpperCamelCase or PascalCase.
Similar to the main method, the printTwice method is public (i.e., it can be invoked from other classes) static and void.
Parameters
A method can specify parameters. The printTwice method above specifies a parameter of String type. The main method passes the argument "Polly likes crackers" to that parameter.
The value provided as an argument must have the same type as the parameter. Sometimes Java can convert an argument from one type to another automatically. For example, if the method requires a double, you can invoke it with an int argument 5 and Java will automatically convert the argument to the equivalent value of type double 5.0.
Because a variable declared inside a method only exists inside that method, such variables are called local variables. That applies to parameters of a method too. For example, In the code above, s cannot be used inside main because it is a parameter of the printTwice method and can only be used inside that method. If you try to use s inside main, you’ll get a compiler error. Similarly, inside printTwice there is no such thing as sentence. That variable belongs to main.
return statements
The return statement allows you to terminate a method before you reach the end of it:
public static void printLogarithm(double x) {
if (x <= 0.0) {
System.out.println("Error: x must be positive.");
return;
}
double result = Math.log(x);
System.out.println("The log of x is " + result);
}
It can be used to return a value from a method too:
public class AreaCalculator{
public static double calculateArea(double radius) {
double result = 3.14 * radius * radius;
return result;
}
public static void main(String[] args) {
double area = calculateArea(12.5);
System.out.println(area);
}
}
Overloading
Java methods can be overloaded. If two methods do the same thing, it is natural to give them the same name. Having more than one method with the same name is called overloading, and it is legal in Java as long as each version has a different method signature (the signature of the method is the method name and ordered list of parameter types) . For example, the following overloading of the method calculateArea is allowed because the method signatures are different (i.e., calculateArea(double) vs calculateArea(double, double)).
public static double calculateArea(double radius) {
//...
}
public static double calculateArea(double height, double width) {
//...
}
Recursion
Methods can be recursive. Here is an example in which the nLines method calls itself recursively:
public static void nLines(int n) {
if (n > 0) {
System.out.println();
nLines(n - 1);
}
}
Resources
- Oracle's tutorials on [methods][parameters]
- Method Overloading in Java a tutorial from javapoint.com. Also mentions the topic of a related topic type promotion.
Exercises
[Key Exercise] getGradeCap Method
Add the following method to the class given below.
public static double getGradeCap(String grade): Returns the CAP value of the givengrade. The mapping from grades to CAP is given below.
| A+ | A | A- | B+ | B | B- | C | Else |
|---|---|---|---|---|---|---|---|
| 5.0 | 5.0 | 4.5 | 4.0 | 3.5 | 3.0 | 2.5 | 0 |
Do not change the code of the main method!
public class Main {
// ADD YOUR CODE HERE
public static void main(String[] args) {
System.out.println("A+: " + getGradeCap("A+"));
System.out.println("B : " + getGradeCap("B"));
}
}
A+: 5.0
B : 3.5
Partial solution:
public static double getGradeCap(String grade) {
double cap = 0;
switch (grade) {
case "A+":
case "A":
cap = 5.0;
break;
case "A-":
cap = 4.5;
break;
case "B+":
cap = 4.0;
break;
case "B":
cap = 3.5;
break;
case "B-":
cap = 3.0;
break;
default:
}
return cap;
}
C++ to Java → Control Flow → Loops
Can use loops
Java has while and for constructs for looping.
while loops
Here is an example while loop:
public static void countdown(int n) {
while (n > 0) {
System.out.println(n);
n = n - 1;
}
System.out.println("Blastoff!");
}
for loops
for loops have the form:
for (initializer; condition; update) {
statement(s);
}
Here is an example:
public static void printTable(int rows) {
for (int i = 1; i <= rows; i = i + 1) {
printRow(i, rows);
}
}
do-while loops
The while and for statements are pretest loops; that is, they test the condition first and at the beginning of each pass through the loop. Java also provides a posttest loop: the do-while statement. This type of loop is useful when you need to run the body of the loop at least once.
Here is an example (from -- Java Tutorial):
class DoWhileDemo {
public static void main(String[] args){
int count = 1;
do {
System.out.println("Count is: " + count);
count++;
} while (count < 11);
}
}
break and continue
A break statement exits the current loop.
Here is an example (from -- Java Tutorial):
class Main {
public static void main(String[] args) {
int[] numbers = new int[] { 1, 2, 3, 0, 4, 5, 0 };
for (int i = 0; i < numbers.length; i++) {
if (numbers[i] == 0) {
break;
}
System.out.print(numbers[i]);
}
}
}
123
[Try the above code on Repl.it]
A continue statement skips the remainder of the current iteration and moves to the next iteration of the loop.
Here is an example (from -- Java Tutorial):
public static void main(String[] args) {
int[] numbers = new int[] { 1, 2, 3, 0, 4, 5, 0 };
for (int i = 0; i < numbers.length; i++) {
if (numbers[i] == 0) {
continue;
}
System.out.print(numbers[i]);
}
}
12345
Enhanced for loops
Since traversing arrays is so common, Java provides an alternative for-loop syntax that makes the code more compact. For example, consider a for loop that displays the elements of an array on separate lines:
for (int i = 0; i < values.length; i++) {
int value = values[i];
System.out.println(value);
}
We could rewrite the loop like this:
for (int value : values) {
System.out.println(value);
}
This statement is called an enhanced for loop. You can read it as, “for each value in values”.
Notice how the single line for (int value : values) replaces the first two lines of the standard for loop.
Resources
- Oracle's tutorials on [
while][for][break/continue]
Exercises
[Key Exercise] getMultipleGradeCaps Method
Add the following method to the class given below.
public static double[] getMultipleGradeCaps(String[] grades): Returns the CAP values of the givengrades. e.g., if the input was the array["A+", "B"], the method returns[5.0, 3.5]. The mapping from grades to CAP is given below.
| A+ | A | A- | B+ | B | B- | C | Else |
|---|---|---|---|---|---|---|---|
| 5.0 | 5.0 | 4.5 | 4.0 | 3.5 | 3.0 | 2.5 | 0 |
Do not change the code of the main method!
public class Main {
// ADD YOUR CODE HERE
public static double getGradeCap(String grade) {
double cap = 0;
switch (grade) {
case "A+":
case "A":
cap = 5.0;
break;
case "A-":
cap = 4.5;
break;
case "B+":
cap = 4.0;
break;
case "B":
cap = 3.5;
break;
case "B-":
cap = 3.0;
break;
case "C":
cap = 2.5;
break;
default:
}
return cap;
}
public static void main(String[] args) {
String[] grades = new String[]{"A+", "A", "A-"};
double[] caps = getMultipleGradeCaps(grades);
for (int i = 0; i < grades.length; i++) {
System.out.println(grades[i] + ":" + caps[i]);
}
}
}
A+:5.0
A:5.0
A-:4.5
Partial solution:
public static double[] getMultipleGradeCaps(String[] grades) {
double[] caps = new double[grades.length];
for (int i = 0; i < grades.length; i++) {
// ...
}
return caps;
}
Paradigms → OOP → Introduction → What
Can describe OOP at a higher level
Object-Oriented Programming (OOP) is a programming paradigm. A programming paradigm guides programmers to analyze programming problems, and structure programming solutions, in a specific way.
Programming languages have traditionally divided the world into two parts—data and operations on data. Data is static and immutable, except as the operations may change it. The procedures and functions that operate on data have no lasting state of their own; they’re useful only in their ability to affect data.
This division is, of course, grounded in the way computers work, so it’s not one that you can easily ignore or push aside. Like the equally pervasive distinctions between matter and energy and between nouns and verbs, it forms the background against which you work. At some point, all programmers—even object-oriented programmers—must lay out the data structures that their programs will use and define the functions that will act on the data.
With a procedural programming language like C, that’s about all there is to it. The language may offer various kinds of support for organizing data and functions, but it won’t divide the world any differently. Functions and data structures are the basic elements of design.
Object-oriented programming doesn’t so much dispute this view of the world as restructure it at a higher level. It groups operations and data into modular units called objects and lets you combine objects into structured networks to form a complete program. In an object-oriented programming language, objects and object interactions are the basic elements of design.
Some other examples of programming paradigms are:
| Paradigm | Programming Languages |
|---|---|
| Procedural Programming paradigm | C |
| Functional Programming paradigm | F#, Haskell, Scala |
| Logic Programming paradigm | Prolog |
Some programming languages support multiple paradigms.
Java is primarily an OOP language but it supports limited forms of functional programming and it can be used to (although not recommended) write procedural code. e.g. se-edu/addressbook-level1
JavaScript and Python support functional, procedural, and OOP programming.
Exercises
Statements about OOP
A) Choose the correct statements
- a. OO is a programming paradigm
- b. OO guides us in how to structure the solution
- c. OO is mainly an abstraction mechanism
- d. OO is a programming language
- e. OO is modeled after how the objects in real world work
B) Choose the correct statements
- a. Java and C++ are OO languages
- b. C language follows the Functional Programming paradigm
- c. Java can be used to write procedural code
- d. Prolog follows the Logic Programming paradigm
A) (a)(b)(c)(e)
Explanation: While many languages support the OO paradigm, OO is not a language itself.
B) Choose the correct statement
(a)(b)(c)(d)
Explanation: C follows the procedural paradigm. Yes, we can write procedural code using OO languages e.g., AddressBook-level1.
Procedural vs OOP
OO is a higher level mechanism than the procedural paradigm.
True.
Explanation: Procedural languages work at the simple data structures (e.g., integers, arrays) and functions level. Because an object is an abstraction over data-related functions, OO works at a higher level.
Paradigms → OOP → Objects → What
Can describe how OOP relates to the real world
Every object has both state (data) and behavior (operations on data). In that, they’re not much different from ordinary physical objects. It’s easy to see how a mechanical device, such as a pocket watch or a piano, embodies both state and behavior. But almost anything that’s designed to do a job does, too. Even simple things with no moving parts such as an ordinary bottle combine state (how full the bottle is, whether or not it’s open, how warm its contents are) with behavior (the ability to dispense its contents at various flow rates, to be opened or closed, to withstand high or low temperatures).
It’s this resemblance to real things that gives objects much of their power and appeal. They can not only model components of real systems, but equally as well fulfill assigned roles as components in software systems.
Object Oriented Programming (OOP) views the world as a network of interacting objects.
A real world scenario viewed as a network of interacting objects:
You are asked to find out the average age of a group of people Adam, Beth, Charlie, and Daisy. You take a piece of paper and pen, go to each person, ask for their age, and note it down. After collecting the age of all four, you enter it into a calculator to find the total. And then, use the same calculator to divide the total by four, to get the average age. This can be viewed as the objects You, Pen, Paper, Calculator, Adam, Beth, Charlie, and Daisy interacting to accomplish the end result of calculating the average age of the four persons. These objects can be considered as connected in a certain network of certain structure.
OOP solutions try to create a similar object network inside the computer’s memory – a sort of virtual simulation of the corresponding real world scenario – so that a similar result can be achieved programmatically.
OOP does not demand that the virtual world object network follow the real world exactly.
Our previous example can be tweaked a bit as follows:
- Use an object called
Mainto represent your role in the scenario. - As there is no physical writing involved, you can replace the
PenandPaperwith an object calledAgeListthat is able to keep a list of ages.
Every object has both state (data) and behavior (operations on data).
| Object | Real World? | Virtual World? | Example of State (i.e. Data) | Examples of Behavior (i.e. Operations) |
|---|---|---|---|---|
| Adam | Name, Date of Birth | Calculate age based on birthday | ||
| Pen | - | Ink color, Amount of ink remaining | Write | |
| AgeList | - | Recorded ages | Give the number of entries, Accept an entry to record | |
| Calculator | Numbers already entered | Calculate the sum, divide | ||
| You/Main | Average age, Sum of ages | Use other objects to calculate |
Every object has an interface and an implementation.
Every real world object has:
- an interface through which other objects can interact with it
- an implementation that supports the interface but may not be accessible to the other object
The interface and implementation of some real-world objects in our example:
- Calculator: the buttons and the display are part of the interface; circuits are part of the implementation.
- Adam: In the context of our 'calculate average age' example, the interface of Adam consists of requests that Adam will respond to, e.g. "Give age to the nearest year, as at Jan 1st of this year" "State your name"; the implementation includes the mental calculation Adam uses to calculate the age which is not visible to other objects.
Similarly, every object in the virtual world has an interface and an implementation.
The interface and implementation of some virtual-world objects in our example:
Adam: the interface might have a methodgetAge(Date asAt); the implementation of that method is not visible to other objects.
Objects interact by sending messages. Both real world and virtual world object interactions can be viewed as objects sending messages to each other. The message can result in the sender object receiving a response and/or the receiver object’s state being changed. Furthermore, the result can vary based on which object received the message, even if the message is identical (see rows 1 and 2 in the example below).
Examples:
| World | Sender | Receiver | Message | Response | State Change |
|---|---|---|---|---|---|
| Real | You | Adam | "What is your name?" | "Adam" | - |
| Real | as above | Beth | as above | "Beth" | - |
| Real | You | Pen | Put nib on paper and apply pressure | Makes a mark on your paper | Ink level goes down |
| Virtual | Main | Calculator (current total is 50) | add(int i): int i = 23 | 73 | total = total + 23 |
Exercises
Describe objects in the given scenario
Consider the following real-world scenario.
Tom read a Software Engineering textbook (he has been assigned to read the book) and highlighted some of the text in it.
Explain the following statements about OOP using the above scenario as an example.
- Object Oriented Programming (OOP) views the world as a network of interacting objects.
- Every object has both state (data) and behavior (operations on data).
- Every object has an interface and an implementation.
- Objects interact by sending messages.
- OOP does not demand that the virtual world object network follow the real world exactly.
[1] Object Oriented Programming (OOP) views the world as a network of interacting objects.
Interacting objects in the scenario: Tom, SE Textbook (Book for short), Text, (possibly) Highlighter
objects usually match nouns in the description
[2] Every object has both state (data) and behavior (operations on data).
| Object | Examples of state | Examples of behavior |
|---|---|---|
Tom |
memory of the text read | read |
Book |
title | show text |
Text |
font size | get highlighted |
[3] Every object has an interface and an implementation.
- Interface of an object consists of how other objects interact with it i.e., what other objects can do to that object.
- Implementation consist of internals of the object that facilitate the interactions but not visible to other objects.
| Object | Examples of interface | Examples of implementation |
|---|---|---|
Tom |
receive reading assignment | understand/memorize the text, read, remember the reading assignment |
Book |
show text, turn page | how pages are bound to the spine |
Text |
read | how characters/words are connected together or fixed to the book |
[4] Objects interact by sending messages.
Examples:
Tomsends messageturn pageto theBook.Tomsends messageshow textto theBook. When theBookshows theText,Tomsends the messagereadto theTextwhich returns the text content toTom.Tomsends messagehighlightto theHighlighterwhile specifying whichTextto highlight. Then theHighlightersends the messagehighlightto the specifiedText.
[5] OOP does not demand that the virtual world object network follow the real world exactly.
Examples:
- A virtual world simulation of the above scenario can omit the
Highlighterobject. Instead, we can teachTextto highlight themselves when requested.
Paradigms → OOP → Objects → Objects as abstractions
Can explain the abstraction aspect of OOP
The concept of Objects in OOP is an abstraction mechanism because it allows us to abstract away the lower level details and work with bigger granularity entities i.e. ignore details of data formats and the method implementation details and work at the level of objects.
Abstraction is a technique for dealing with complexity. It works by establishing a level of complexity we are interested in, and suppressing the more complex details below that level.
You can deal with a Person object that represents the person Adam and query the object for Adam's age instead of dealing with details such as Adam’s date of birth (DoB), in what format the DoB is stored, the algorithm used to calculate the age from the DoB, etc.
Paradigms → OOP → Objects → Encapsulation of objects
Can explain the encapsulation aspect of OOP
Encapsulation protects an implementation from unintended actions and from inadvertent access.
-- Object-Oriented Programming with Objective-C, Apple
An object is an encapsulation of some data and related behavior in terms of two aspects:
1. The packaging aspect: An object packages data and related behavior together into one self-contained unit.
2. The information hiding aspect: The data in an object is hidden from the outside world and are only accessible using the object's interface.
Exercises
Choose the correct statement
Choose the correct statement.
- a. An object is an encapsulation because it packages data and behavior into one bundle.
- b. An object is an encapsulation because it lets us think in terms of higher level concepts such as Students rather than student-related functions and data separately.
Don't confuse encapsulation with abstraction.
(a)
Explanation: The second statement should be: An object is an abstraction encapsulation because it lets ...
Paradigms → OOP → Classes → What
Can explain the relationship between classes and objects
Writing an OOP program is essentially writing instructions that the computer will use to,
- create the virtual world of the object network, and
- provide it the inputs to produce the outcome you want.
A class contains instructions for creating a specific kind of objects. It turns out sometimes multiple objects keep the same type of data and have the same behavior because they are of the same kind. Instructions for creating a 'kind' (or ‘class’) of objects can be done once and those same instructions can be used to i.e. create instances ofinstantiate objects of that kind. You call such instructions a Class.
Classes and objects in an example scenario
Consider the example of writing an OOP program to calculate the average age of Adam, Beth, Charlie, and Daisy.
Instructions for creating objects Adam, Beth, Charlie, and Daisy will be very similar because they are all of the same kind: they all represent ‘persons’ with the same interface, the same kind of data (i.e. name, dateOfBirth, etc.), and the same kind of behavior (i.e. getAge(Date), getName(), etc.). Therefore, you can have a class called Person containing instructions on how to create Person objects and use that class to instantiate objects Adam, Beth, Charlie, and Daisy.
Similarly, you need classes AgeList, Calculator, and Main classes to instantiate one each of AgeList, Calculator, and Main objects.
| Class | Objects |
|---|---|
Person |
objects representing Adam, Beth, Charlie, Daisy |
AgeList |
an object to represent the age list |
Calculator |
an object to do the calculations |
Main |
an object to represent you (i.e., the one who manages the whole operation) |
Exercises
Identify Classes and Objects
Consider the following scenario. If you were to simulate this in an OOP program, what are the classes and the objects you would use?
A customer (name: John) gave a cheque to the cashier (name: Peter) to pay for the LoTR and GoT books he bought.
| Class | Objects |
|---|---|
Customer |
john |
Book |
LoTR, GoT |
Cheque |
chequeJohnGave |
Cashier |
peter |
Classes for CityConnect app
Assume you are writing a CLI program called CityConnect for storing and querying distances between cities. The behavior is as follows:
Welcome to CityConnect!
Enter command: addroute Clementi BuonaVista 12
Route from Clementi to BuonaVista with distance 12km added
Enter command: getdistance Clementi BuonaVista
Distance from Clementi to BuonaVista is 12
Enter command: getdistance Clementi JurongWest
No route exists from Clementi to JurongWest!
Enter command: addroute Clementi JurongWest 24
Route from Clementi to JurongWest with distance 24km added
Enter command: getdistance Clementi JurongWest
Distance from Clementi to JurongWest is 24
Enter command: exit
What classes would you have in your code if you write your program based on the OOP paradigm?
One class you can have is Route
C++ to Java → Objects → Using Java objects
Can use in-built Java objects
Java is an "object-oriented" language, which means that it uses objects to represent data and provide methods related to them. Object types are called classes e.g., you can use String objects in Java and those objects belong to the String class.
importing
Java comes with many inbuilt classes which are organized into packages. Here are some examples:
| package | Some example classes in the package |
|---|---|
java.lang |
String, Math, System |
Before using a class in your code, you need to import the class. import statements appear at the top of the code.
This example imports the java.awt.Point class (i.e., the Point class in the java.awt package) -- which can be used to represent the coordinates of a location in a Cartesian plane -- and use it in the main method.
In mathematical notation, points are often written in parentheses with a comma separating the coordinates. For example, (0,0) indicates the origin, and (x,y) indicates the point x units to the right and y units up from the origin.
import java.awt.Point;
public class Main{
public static void main(String[] args) {
Point spot = new Point(3, 4);
int x = spot.x;
System.out.println(x);
}
}
You might wonder why we can use the System class without importing it. System belongs to the java.lang package, which is imported automatically.
new operator
To create a new object, you have to use the new operator
This line shows how to create a new Point object using the new operator:
Point spot = new Point(3, 4);
Exercises
[Key Exercise] create Rectangle objects
Update the code below to create a new Rectangle object as described in the code comments, to produce the given output.
- The
Rectangleclass is found in thejava.awtpackage. - The parameters you need to supply when creating new
Rectangleobjects are(int x, int y, int width, int height).
public class Main {
public static void main(String[] args) {
Rectangle r;
// TODO create a Rectangle object that has the properties x=0, y=0, width=5, height=10
// assign it to r
System.out.println(r);
}
}
java.awt.Rectangle[x=0,y=0,width=5,height=10]
- Import the
java.awt.Rectangleclass - This is how you create the required object
new Rectangle(0, 0, 5, 10)
C++ to Java → Objects → Instance members
Can use instance members of objects
Variables that belong to an object are called attributes (or fields).
To access an attribute of an object, Java uses dot notation.
The code below uses spot.x which means "go to the object spot refers to, and get the value of the attribute x."
Point spot = new Point(3, 4);
int sum = spot.x * spot.x + spot.y * spot.y;
System.out.println(spot.x + ", " + spot.y + ", " + sum);
3, 4, 25
You can i.e., change/modifymutate an object by assigning a different value to its attributes.
This example changes the x value of the Point object to 5.
Point spot = new Point(3, 4);
spot.x = 5;
System.out.println(spot.x + ", " + spot.y);
5, 4
Java uses the dot notation to invoke methods on an object too.
This example invokes the translate method on a Point object so that it moves to a different location.
Point spot = new Point(3, 4);
System.out.println(spot.x + ", " + spot.y);
spot.translate(5,5);
System.out.println(spot.x + ", " + spot.y);
3, 4
8, 9
Exercises
[Key Exercise] use Rectangle objects
Update the code below as described in code comments, to produce the given output.
import java.awt.Rectangle;
public class Main {
public static void main(String[] args) {
Rectangle r = new Rectangle(0, 0, 4, 6);
System.out.println(r);
int area;
//TODO: add a line below to calculate the area using width and height properties of r
// and assign it to the variable area
System.out.println("Area: " + area);
//TODO: add a line here to set the size of r to 8x10 (width x height)
//Recommended: use the setSize(int width, int height) method of the Rectangle object
System.out.println(r);
}
}
java.awt.Rectangle[x=0,y=0,width=4,height=6]
Area: 24
java.awt.Rectangle[x=0,y=0,width=8,height=10]
- Area can be calculated as
r.width * r.height - Setting the size can be done as
r.setSize(8, 10)
C++ to Java → Objects → Passing objects around
Can pass objects between methods
You can pass objects as parameters to a method in the usual way.
The printPoint method below takes a Point object as an argument and displays its attributes in (x,y) format.
public static void printPoint(Point p) {
System.out.println("(" + p.x + ", " + p.y + ")");
}
public static void main(String[] args) {
Point spot = new Point(3, 4);
printPoint(spot);
}
3, 4
You can return an object from a method too.
The java.awt package also provides a class called Rectangle. Rectangle objects are similar to points, but they have four attributes: x, y, width, and height. The findCenter method below takes a Rectangle as an argument and returns a Point that corresponds to the center of the rectangle:
public static Point findCenter(Rectangle box) {
int x = box.x + box.width / 2;
int y = box.y + box.height / 2;
return new Point(x, y);
}
The return type of this method is Point. The last line creates a new Point object and returns a reference to it.
null and NullPointerException
null is a special value that means "no object". You can assign null to a variable to indicate that the variable is 'empty' at the moment. However, if you try to use a null value, either by accessing an attribute or invoking a method, Java throws a NullPointerException.
In this example, the variable spot is assigned a null value. As a result, trying to access spot.x attribute or invoking the spot.translate method results in a NullPointerException.
Point spot = null;
int x = spot.x; // NullPointerException
spot.translate(50, 50); // NullPointerException
On the other hand, it is legal to return null from a method or to pass a null reference as an argument to a method.
Returning null from a method.
public static Point createCopy(Point p) {
if (p == null) {
return null; // return null if p is null
}
// create a new object with same x,y values
return new Point(p.x, p.y);
}
Passing null as the argument.
Point result = createCopy(null);
System.out.println(result);
null
It is possible to have multiple variables that refer to the same object.
Notice how p1 and p2 are aliases for the same object. When the object is changed using the variable p1, the changes are visible via p2 as well (and vice versa), because they both point to the same Point object.
Point p1 = new Point(0,0);
Point p2 = p1;
System.out.println("p1: " + p1.x + ", " + p1.y);
System.out.println("p2: " + p2.x + ", " + p2.y);
p1.x = 1;
p2.y = 2;
System.out.println("p1: " + p1.x + ", " + p1.y);
System.out.println("p2: " + p2.x + ", " + p2.y);
p1: 0, 0
p2: 0, 0
p1: 1, 2
p2: 1, 2
Java does not have explicit pointers (and other related things such as pointer de-referencing and pointer arithmetic). When an object is passed into a method as an argument, the method gains access to the original object. If the method changes the object it received, the changes are retained in the object even after the method has completed.
Note how p3 retains changes done to it by the method swapCoordinates even after the method has completed executing.
public static void swapCoordinates(Point p){
int temp = p.x;
p.x = p.y;
p.y = temp;
}
public static void main(String[] args) {
Point p3 = new Point(2,3);
System.out.println("p3: " + p3.x + ", " + p3.y);
swapCoordinates(p3);
System.out.println("p3: " + p3.x + ", " + p3.y);
}
p3: 2, 3
p3: 3, 2
Exercises
[Key Exercise] pass objects to move method
Add a method move(Point p, Rectangle r) to the code below, to produce the given output. The behavior of the method is as follows:
- Returns
nulland does nothing if eitherporris null - Returns a new
Pointobject that has attributesxandythat match those ofr - Does not modify
p - Updates
rso that its attributesxandymatch those ofp
import java.awt.Point;
import java.awt.Rectangle;
public class Main {
//TODO add your method here
public static void main(String[] args) {
Point p1 = new Point(0, 0);
Rectangle r1 = new Rectangle(2, 3, 5, 6);
System.out.println("arguments: " + p1 + ", " + r1);
Point p2 = move(p1, r1);
System.out.println("argument point after method call: " + p1);
System.out.println("argument rectangle after method call: " + r1);
System.out.println("returned point: " + p2);
System.out.println(move(null, null));
}
}
arguments: java.awt.Point[x=0,y=0], java.awt.Rectangle[x=2,y=3,width=5,height=6]
argument point after method call: java.awt.Point[x=0,y=0]
argument rectangle after method call: java.awt.Rectangle[x=0,y=0,width=5,height=6]
returned point: java.awt.Point[x=2,y=3]
null
Partial solution:
public static Point move(Point p, Rectangle r){
if (p == null || r == null){
// ...
}
Point newPoint = new Point(r.x, r.y);
r.x = p.x;
// ...
return newPoint;
}
C++ to Java → Objects → Garbage collection
Can explain Java garbage collection
What happens when no variables refer to an object?
Point spot = new Point(3, 4);
spot = null;
The first line creates a new Point object and makes spot refer to it. The second line changes spot so that instead of referring to the object, it refers to nothing. If there are no references to an object, there is no way to access its attributes or invoke a method on it. From the programmer’s view, it ceases to exist. However, it’s still present in the computer’s memory, taking up space.
In Java, you don’t have to delete objects you create when they are no longer needed. As your program runs, the system automatically looks for stranded objects and reclaims them; then the space can be reused for new objects. This process is called garbage collection. You don’t have to do anything to make garbage collection happen, and in general don’t have to be aware of it. But in high-performance applications, you may notice a slight delay every now and then when Java reclaims space from discarded objects.
C++ to Java → Classes → Defining classes
Can define Java classes
As you know,
- Defining a class introduces a new object type.
- Every object belongs to some object type; that is, it is an instance of some class.
- A class definition is like a template for objects: it specifies what attributes the objects have and what methods can operate on them.
- The
newoperator instantiates objects, that is, it creates new instances of a class. - The methods that operate on an object type are defined in the class for that object.
Here's a class called Time, intended to represent a moment in time. It has three attributes and no methods.
public class Time {
private int hour;
private int minute;
private int second;
}
You can give a class any name you like. The Java convention is to use e.g., MyHelloWord rather than myHelloWorld or myhelloword or my_hello_worldPascalCase format for class names.
The code is there are exceptions to this ruleusually placed in a file whose name matches the class e.g., the Time class should be in a file named Time.java.
When a class is public (e.g., the Time class in the above example) it can be used in other classes. But the Attributes are also called instance variables, because each instance has its own variables.instance variables that are private (e.g., the hour, minute and second attributes of the Time class) can only be accessed from inside the Time class.
Constructors
The syntax for special methods that construct the object and initialize the instance variablesconstructors is similar to that of other methods, except:
- The name of the constructor is the same as the name of the class.
- The keyword
staticis omitted. - Does not return anything. A constructor returns the created object by default.
When you invoke new, Java creates the object and calls your constructor to initialize the instance variables. When the constructor is done, it returns a reference to the new object.
Here is an example constructor for the Time class:
public Time() {
hour = 0;
minute = 0;
second = 0;
}
This constructor does not take any arguments. Each line initializes an instance variable to 0 (which in this example means midnight).
Now you can create Time objects.
Time time = new Time();
Like other methods, constructors can be i.e., you can provide multiple constructors with different parametersoverloaded.
You can add another constructor to the Time class to allow creating Time objects that are initialized to a specific time:
public Time(int h, int m, int s) {
hour = h;
minute = m;
second = s;
}
Here's how you can invoke the new constructor:
Time justBeforeMidnight = new Time(11, 59, 59);
this keyword
The this keyword is a reference variable in Java that refers to the i.e., the enclosing object, or myselfcurrent object. You can use this the same way you use the name of any other object. For example, you can read and write the instance variables of this, and you can pass this as an argument to other methods. But you do not declare this, and you can’t make an assignment to it.
In the following version of the constructor, the names and types of the parameters are the same as the instance variables (parameters don’t have to use the same names, but that’s a common style). As a result, the parameters shadow (or hide) the instance variables, so the keyword this is necessary to tell them apart.
public Time(int hour, int minute, int second) {
this.hour = hour;
this.minute = minute;
this.second = second;
}
this can be used to refer to a constructor of a class within the same class too.
In this example the constructor Time() uses the this keyword to call its own overloaded constructor Time(int, int, int)
public Time() {
this(0, 0, 0); // call the overloaded constructor
}
public Time(int hour, int minute, int second) {
// ...
}
Instance methods
You can add methods to a class which can then be used from the objects of that class. These instance methods do not have the static keyword in the method signature. Instance methods can access attributes of the class.
Here's how you can add a method to the Time class to get the number of seconds passed till midnight.
public int secondsSinceMidnight() {
return hour*60*60 + minute*60 + second;
}
Here's how you can use that method.
Time t = new Time(0, 2, 5);
System.out.println(t.secondsSinceMidnight() + " seconds since midnight!");
Exercises
[Key Exercise] define a Circle class
Define a Circle class so that the code given below produces the given output. The nature of the class is as follows:
- Attributes(all
private):int x,int y: represents the location of the circledouble radius: the radius of the circle
- Constructors:
Circle(): initializesx,y,radiusto 0Circle(int x, int y, double radius): initializes the attributes to the given values
- Methods:
getArea():int
Returns the area of the circle as anintvalue (notdouble). Calculated as Pi * (radius)2
You can convert adoubleto anintusing(int)e.g.,x = (int)2.25givesxthe value2.
You can useMath.PIto get the value of Pi
You can useMath.pow()to raise a number to a specific power e.g.,Math.pow(3, 2)calculates32
public class Main {
public static void main(String[] args) {
Circle c = new Circle();
System.out.println(c.getArea());
c = new Circle(1, 2, 5);
System.out.println(c.getArea());
}
}
0
78
- Put the
Circleclass in a file calledCircle.java
Partial solution:
public class Circle {
private int x;
// ...
public Circle(){
this(0, 0, 0);
}
public Circle(int x, int y, double radius){
this.x = x;
// ...
}
public int getArea(){
double area = Math.PI * Math.pow(radius, 2);
return (int)area;
}
}
C++ to Java → Classes → Getters and setters
Can define getters and setters
As the instance variables of Time are private, you can access them from within the Time class only. To compensate, you can provide methods to access attributes:
public int getHour() {
return hour;
}
public int getMinute() {
return minute;
}
public int getSecond() {
return second;
}
Methods like these are formally called “accessors”, but more commonly referred to as getters. By convention, the method that gets a variable named something is called getSomething.
Similarly, you can provide setter methods to modify attributes of a Time object:
public void setHour(int hour) {
this.hour = hour;
}
public void setMinute(int minute) {
this.minute = minute;
}
public void setSecond(int second) {
this.second = second;
}
Exercises
[Key Exercise] add getters/setters to the Circle class
Consider the Circle class below:
public class Circle {
private int x;
private int y;
private double radius;
public Circle(){
this(0, 0, 0);
}
public Circle(int x, int y, double radius){
this.x = x;
this.y = y;
this.radius = radius;
}
public int getArea(){
double area = Math.PI * Math.pow(radius, 2);
return (int)area;
}
}
Update it as follows so that code given below produces the given output.
- Add getter/setter methods for all three attributes
- Update the setters and constructors such that if the radius supplied is negative, the code automatically set the radius to 0 instead.
public class Main {
public static void main(String[] args) {
Circle c = new Circle(1,2, 5);
c.setX(4);
c.setY(5);
c.setRadius(6);
System.out.println("x : " + c.getX());
System.out.println("y : " + c.getY());
System.out.println("radius : " + c.getRadius());
System.out.println("area : " + c.getArea());
c.setRadius(-5);
System.out.println("radius : " + c.getRadius());
c = new Circle(1, 1, -4);
System.out.println("radius : " + c.getRadius());
}
}
x : 4
y : 5
radius : 6.0
area : 113
radius : 0.0
radius : 0.0
Partial solution:
public Circle(int x, int y, double radius){
setX(x);
setY(y);
setRadius(radius);
}
public void setRadius(double radius) {
this.radius = Math.max(radius, 0);
}
Project Management → Revision Control → What
Can explain revision control
Revision control is the process of managing multiple versions of a piece of information. In its simplest form, this is something that many people do by hand: every time you modify a file, save it under a new name that contains a number, each one higher than the number of the preceding version.
Manually managing multiple versions of even a single file is an error-prone task, though, so software tools to help automate this process have long been available. The earliest automated revision control tools were intended to help a single user to manage revisions of a single file. Over the past few decades, the scope of revision control tools has expanded greatly; they now manage multiple files, and help multiple people to work together. The best modern revision control tools have no problem coping with thousands of people working together on projects that consist of hundreds of thousands of files.
Revision control software will track the history and evolution of your project, so you don't have to. For every change, you'll have a log of who made it; why they made it; when they made it; and what the change was.
Revision control software makes it easier for you to collaborate when you're working with other people. For example, when people more or less simultaneously make potentially incompatible changes, the software will help you to identify and resolve those conflicts.
It can help you to recover from mistakes. If you make a change that later turns out to be an error, you can revert to an earlier version of one or more files. In fact, a really good revision control tool will even help you to efficiently figure out exactly when a problem was introduced.
It will help you to work simultaneously on, and manage the drift between, multiple versions of your project. Most of these reasons are equally valid, at least in theory, whether you're working on a project by yourself, or with a hundred other people.
-- [adapted from bryan-mercurial-guide]
Mercurial: The Definitive Guide by Bryan O'Sullivan retrieved on 2012/07/11
RCS: Revision control software are the software tools that automate the process of Revision Control i.e. managing revisions of software artifacts.
Revision: A revision (some seem to use it interchangeably with version while others seem to distinguish the two -- here, let us treat them as the same, for simplicity) is a state of a piece of information at a specific time that is a result of some changes to it e.g., if you modify the code and save the file, you have a new revision (or a version) of that file.
Revision control software are also known as Version Control Software (VCS), and by a few other names.
Exercises
What does RCS stand for?
Revision Control Software
What is a Revision?
In the context of RCS, what is a Revision? Give an example.
A revision (some seem to use it interchangeably with version while others seem to distinguish the two -- here, let us treat them as the same, for simplicity) is a state of a piece of information at a specific time that is a result of some changes to it. For example, take a file containing program code. If you modify the code and save the file, you have a new revision (or a version) of that file.
Which of these is not considered a benefit of a typical RCS?
- a. Help a single user manage revisions of a single file
- b. Help a developer recover from an incorrect modification to a code file
- c. Make it easier for a group of developers to collaborate on a project
- d. Manage the drift between multiple versions of your project
- e. Detect when multiple developers make incompatible changes to the same file
- f. All of them are benefits of RCS
f
Explain RCS in a team project context
Suppose you are doing a team project with Tom, Dick, and Harry, all of whom have not even heard of the term RCS. How do you explain RCS to them as briefly as possible, using the project as an example?
Project Management → Revision Control → Repositories
Can explain repositories
Repository (repo for short): The database of the history of a directory being tracked by an RCS software (e.g. Git).
The repository is the database where the meta-data about the revision history are stored. Suppose you want to apply revision control on files in a directory called ProjectFoo. In that case, you need to set up a repo (short for repository) in the ProjectFoo directory, which is referred to as the working directory of the repo. For example, Git uses a hidden folder named .git inside the working directory.
You can have multiple repos in your computer, each repo revision-controlling files of a different working directory, for examples, files of different projects.
Exercises
What is a repo?
In the context of RCS, what is a repo?
Tools → Git and GitHub → init: Getting started
Project Management → Revision Control → Repositories
Can create a local Git repo
Let's take your first few steps in your Git (with GitHub) journey.
0. Take a peek at the full picture(?). Optionally, if you are the sort who prefers to have some sense of the full picture before you get into the nitty-gritty details, watch the video in the panel below:
Git Overview
1. The first step is to install SourceTree, which is Git + a GUI for Git. If you prefer to use Git via the command line (i.e., without a GUI), you can install Git instead.
2. Next, initialize a repository. Let us assume you want to version control content in a specific directory. In that case, you need to initialize a Git repository in that directory. Here are the steps:
Create a directory for the repo (e.g., a directory named things).
Windows: Click File → Clone/New…. Click on Create button.
Mac: New... → Create New Repository.
Enter the location of the directory (Windows version shown below) and click Create.
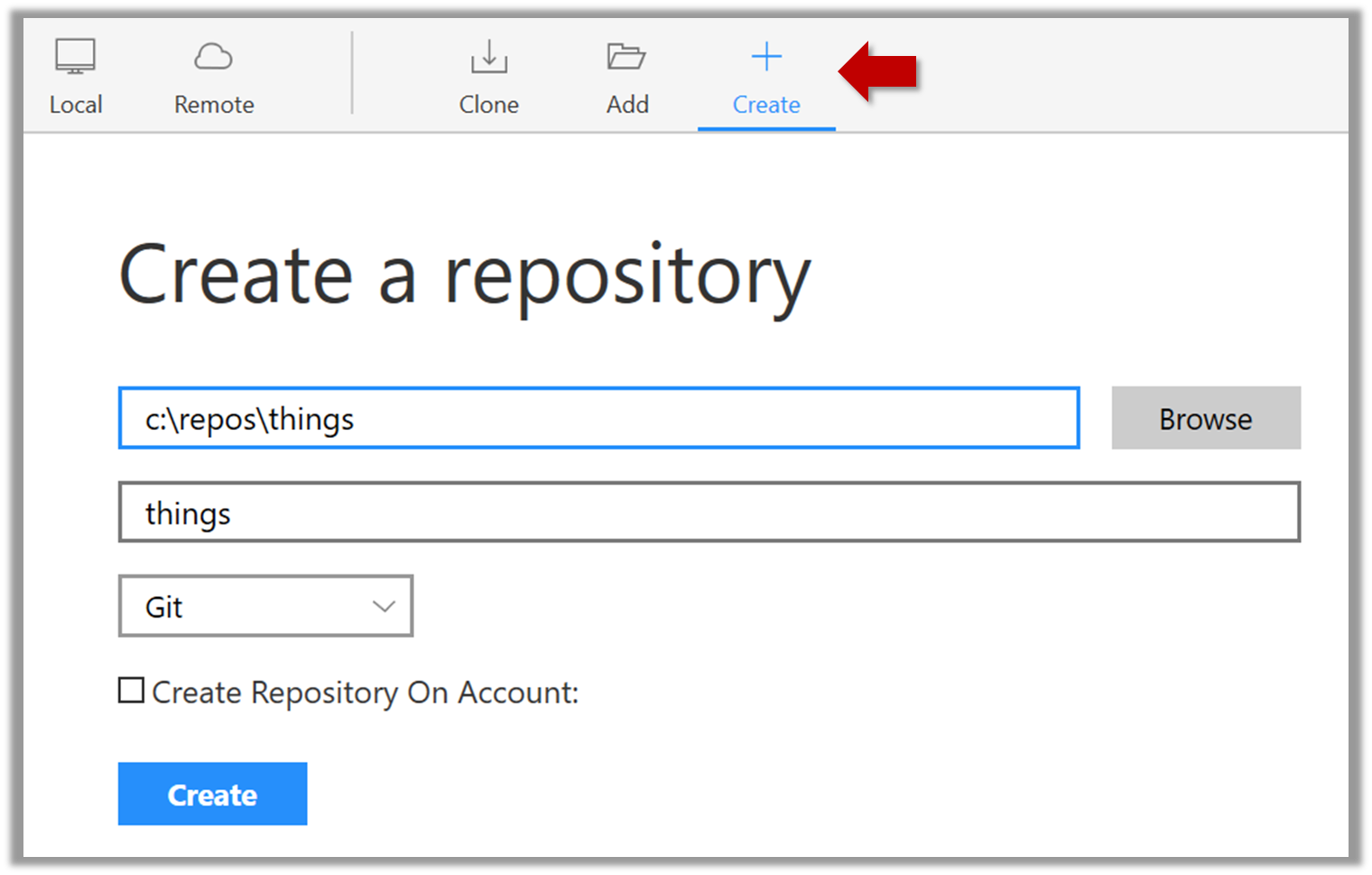
Go to the things folder and observe how a hidden folder .git has been created.
Windows: you might have to configure Windows Explorer to show hidden files.
Open a Git Bash Terminal.
If you installed SourceTree, you can click the Terminal button to open a GitBash terminal.
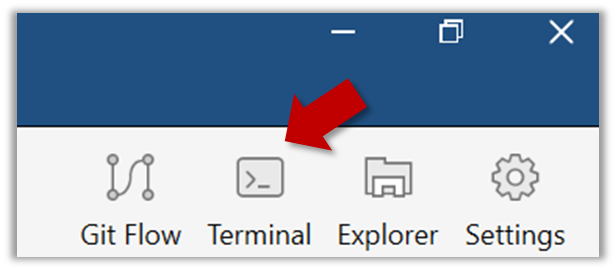
Navigate to the things directory.
Use the command git init which should initialize the repo.
$ git init
Initialized empty Git repository in c:/repos/things/.git/
You can use the command ls -a to view all files, which should show the .git directory that was created by the previous command.
$ ls -a
. .. .git
You can also use the git status command to check the status of the newly-created repo. It should respond with something like the following:
git status
# On branch master
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)
Project Management → Revision Control → Saving history
Can explain saving history
Tracking and ignoring
In a repo, you can specify which files to track and which files to ignore. Some files such as temporary log files created during the build/test process should not be revision-controlled.
Staging and committing
Committing saves a snapshot of the current state of the tracked files in the revision control history. Such a snapshot is also called a commit (i.e. the noun).
When ready to commit, you first stage the specific changes you want to commit. This intermediate step allows you to commit only some changes while saving other changes for a later commit.
Tools → Git and GitHub → commit: Saving changes to history
Git & GitHub → Init
Can commit using Git
After initializing a repository, Git can help you with revision controlling files inside the working directory. However, it is not automatic. It is up to you to tell Git which of your changes (aka revisions) should be committed to its memory for later use. Saving changes into Git's memory in that way is often called committing and a change saved to the revision history is called a commit.
Working directory: the root directory revision-controlled by Git (e.g., the directory in which the repo was initialized).
Commit (noun): a change (aka a revision) saved in the Git revision history.
(verb): the act of creating a commit i.e., saving a change in the working directory into the Git revision history.
Here are the steps you can follow to learn how to work with Git commits:
1. Do some changes to the content inside the working directory e.g., create a file named fruits.txt in the things directory and add some dummy text to it.
2. Observe how the file is detected by Git.
The file is shown as ‘unstaged’.
You can use the git status command to check the status of the working directory.
git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# a.txt
nothing added to commit but untracked files present (use "git add" to track)
3. Stage the changes to commit: Although Git has detected the file in the working directory, it will not do anything with the file unless you tell it to. Suppose you want to commit the current changes to the file. First, you should stage the file.
Stage (verb): Instructing Git to prepare a file for committing.
Select the fruits.txt and click on the Stage Selected button.
fruits.txt should appear in the Staged files panel now.
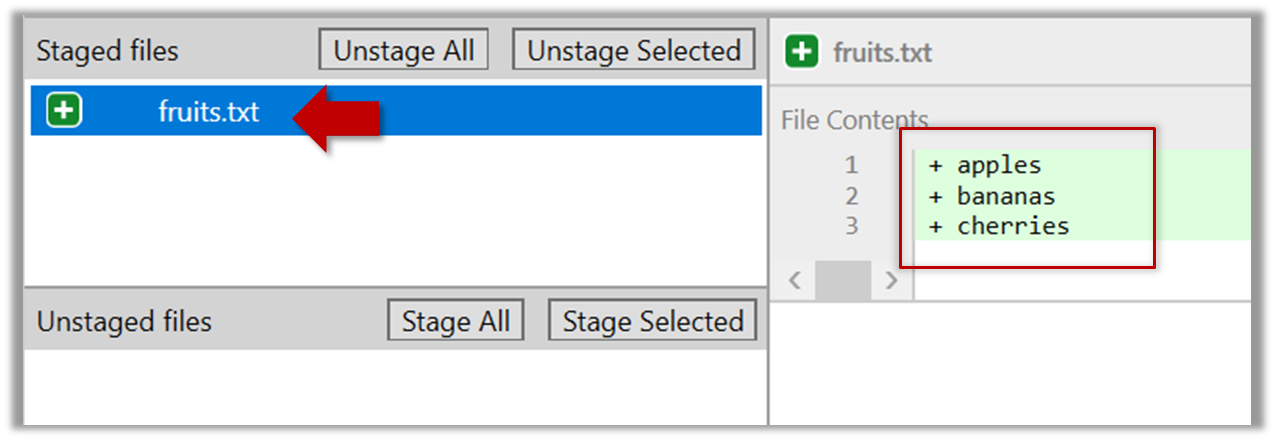
You can use the stage or the add command (they are synonyms, add is the more popular choice) to stage files.
git add fruits.txt
git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: fruits.txt
#
4. Commit the staged version of fruits.txt.
Click the Commit button, enter a commit message e.g. add fruits.txt into the text box, and click Commit.
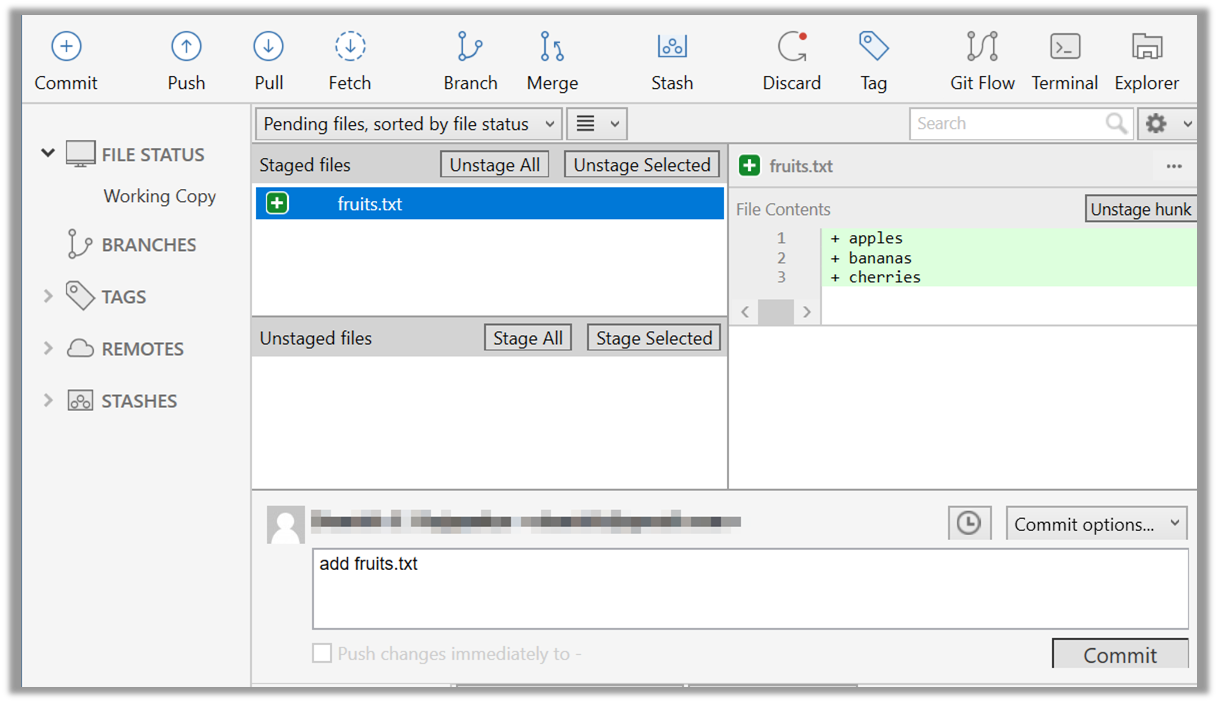
Use the commit command to commit. The -m switch is used to specify the commit message.
git commit -m "add fruits.txt"
You can use the log command to see the commit history.
git log
commit 8fd30a6910efb28bb258cd01be93e481caeab846
Author: … < … @... >
Date: Wed Jul 5 16:06:28 2017 +0800
Add fruits.txt
Note the existence of something called the master branch. Git allows you to have multiple branches (i.e. it is a way to evolve the content in parallel) and Git auto-creates a branch named master on which the commits go on by default.
5. Do a few more commits.
-
Make some changes to
fruits.txt(e.g. add some text and delete some text). Stage the changes, and commit the changes using the same steps you followed before. You should end up with something like this.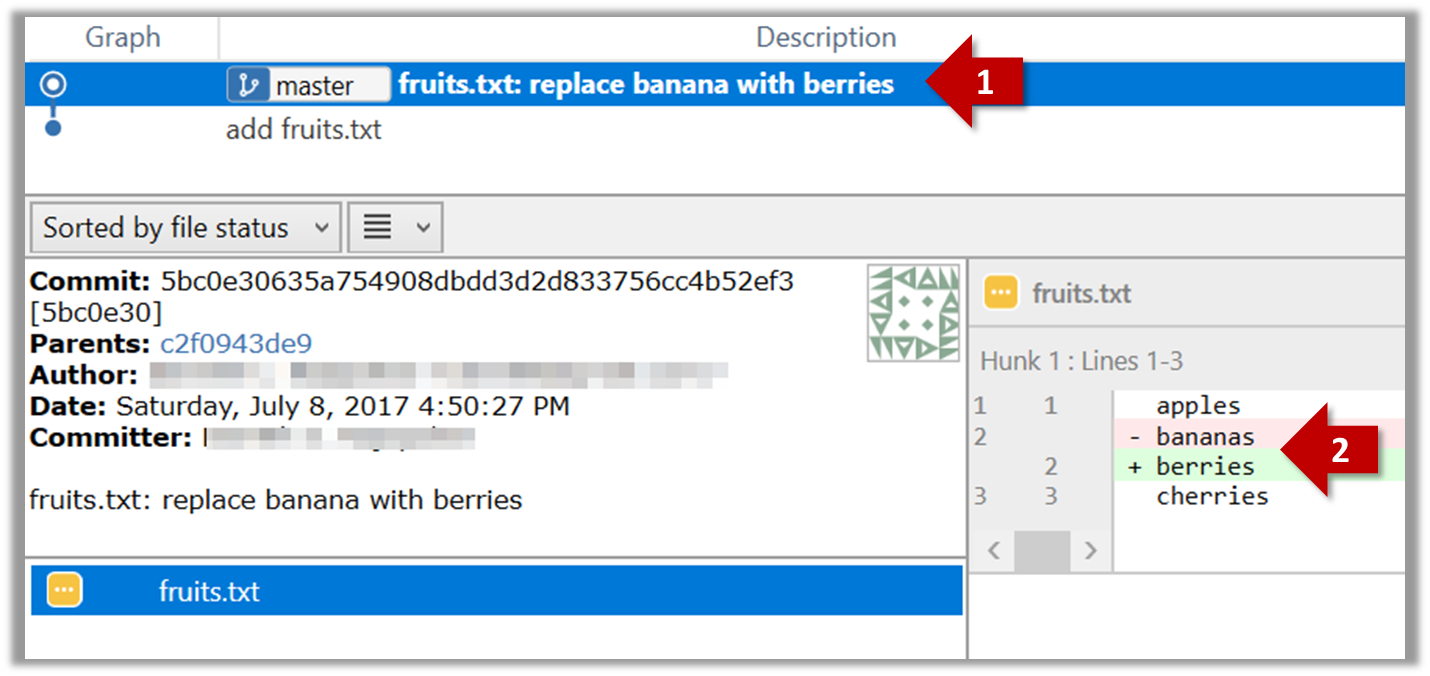
-
Next, add two more files
colors.txtandshapes.txtto the same working directory. Add a third commit to record the current state of the working directory.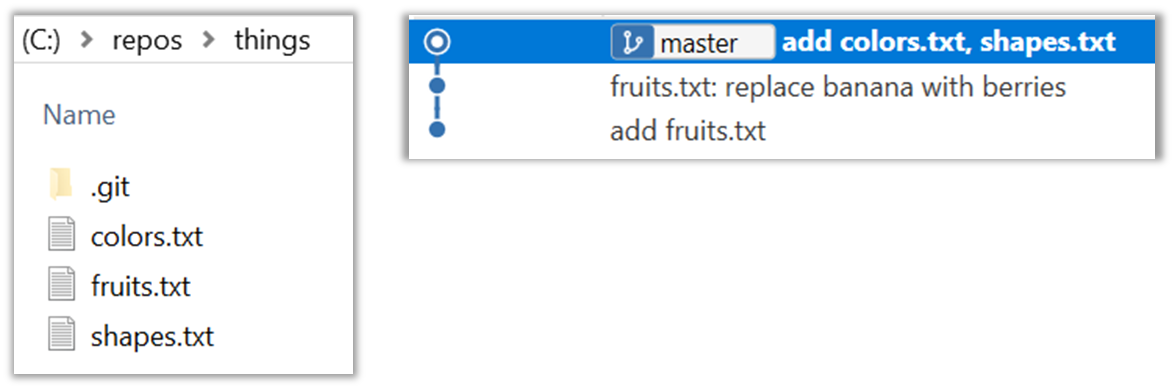
6. See the revision graph: Note how commits form a path-like structure aka the revision tree/graph. In the revision graph, each commit is shown as linked to its 'parent' commit (i.e., the commit before it).
To see the revision graph, click on the History item on the menu on the right edge of SourceTree.
The gitk command opens a rudimentary graphical view of the revision graph.
Resources
- Try Git is an online simulation/tutorial of Git basics. You can try its first few steps to solidify what you have learned in this LO.
Tools → Git and GitHub → Omitting files from revision control
Revision Control: Saving History
Can set Git to ignore files
Often, there are files inside the Git working folder that you don't want to revision-control e.g., temporary log files. Follow the steps below to learn how to configure Git to ignore such files.
1. Add a file into your repo's working folder that you supposedly don't want to revision-control e.g., a file named temp.txt. Observe how Git has detected the new file.
2. Tell Git to ignore that file:
The file should be currently listed under Unstaged files. Right-click it and choose Ignore…. Choose Ignore exact filename(s) and click OK.
Observe that a file named .gitignore has been created in the working directory root and has the following line in it.
temp.txt
Create a file named .gitignore in the working directory root and add the following line in it.
temp.txt
The .gitignore file
The .gitignore file tells Git which files to ignore when tracking revision history. That file itself can be either revision controlled or ignored.
-
To version control it (the more common choice – which allows you to track how the
.gitignorefile changes over time), simply commit it as you would commit any other file. -
To ignore it, follow the same steps you followed above when you set Git to ignore the
temp.txtfile. -
It supports file patterns e.g., adding
temp/*.tmpto the.gitignorefile prevents Git from tracking any.tmpfiles in thetempdirectory.
More information about the .gitignore file: git-scm.com/docs/gitignore
Project Management → Revision Control → Remote repositories
Can explain remote repositories
Remote repositories are repos that are hosted on remote computers and allow remote access. They are especially useful for sharing the revision history of a codebase among team members of a multi-person project. They can also serve as a remote backup of your codebase.
It is possible to set up your own remote repo on a server, but the easier option is to use a remote repo hosting service such as GitHub or BitBucket.
You can clone a repo to create a copy of that repo in another location on your computer. The copy will even have the revision history of the original repo i.e., identical to the original repo. For example, you can clone a remote repo onto your computer to create a local copy of the remote repo.
When you clone from a repo, the original repo is commonly referred to as the upstream repo. A repo can have multiple upstream repos. For example, let's say a repo repo1 was cloned as repo2 which was then cloned as repo3. In this case, repo1 and repo2 are upstream repos of repo3.
You can pull from one repo to another, to receive new commits in the second repo, if the repos have a shared history. Let's say some new commits were added to the upstream repo is a term used to refer to the repo you cloned fromupstream repo after you cloned it and you would like to copy over those new commits to your own clone i.e., sync your clone with the upstream repo. In that case, you pull from the upstream repo to your clone.
You can push new commits in one repo to another repo which will copy the new commits onto the destination repo. Note that pushing to a repo requires you to have write-access to it. Furthermore, you can push between repos only if those repos have a shared history among them (i.e., one was created by copying the other at some point in the past).
Cloning, pushing, and pulling can be done between two local repos too, although it is more common for them to involve a remote repo.
A repo can work with any number of other repositories as long as they have a shared history e.g., repo1 can pull from (or push to) repo2 and repo3 if they have a shared history between them.
A fork is a remote copy of a remote repo. As you know, cloning creates a local copy of a repo. In contrast, forking creates a remote copy of a Git repo hosted on GitHub. This is particularly useful if you want to play around with a GitHub repo but you don't have write permissions to it; you can simply fork the repo and do whatever you want with the fork as you are the owner of the fork.
A pull request (PR for short) is a mechanism for contributing code to a remote repo, i.e., "I'm requesting you to pull my proposed changes to your repo". For this to work, the two repos must have a shared history. The most common case is sending PRs from a fork to its upstream repo is a repo you forked fromupstream repo.
Here is a scenario that includes all the concepts introduced above (click inside the slide to advance the animation):
Tools → Git and GitHub → clone: Copying a repo
Project Management → Revision Control → Remote Respositories
Can clone a remote repo
Given below is an example scenario you can try yourself to learn Git cloning.
You can clone a repo to create a copy of that repo in another location on your computer. The copy will even have the revision history of the original repo i.e., identical to the original repo. For example, you can clone a remote repo onto your computer to create a local copy of the remote repo.
Suppose you want to clone the sample repo samplerepo-things to your computer.
Note that the URL of the GitHub project is different from the URL you need to clone a repo in that GitHub project. e.g.
GitHub project URL: https://github.com/se-edu/samplerepo-things
Git repo URL: https://github.com/se-edu/samplerepo-things.git (note the .git at the end)
File → Clone / New… and provide the URL of the repo and the destination directory.
You can use the clone command to clone a repo.
Follow the instructions given here.
Tools → Git and GitHub → Fork: Creating a remote copy
Tools → Git & GitHub → Pull
Can fork a repo
Given below is a scenario you can try in order to learn how to fork a repo:.
A fork is a remote copy of a remote repo. As you know, cloning creates a local copy of a repo. In contrast, forking creates a remote copy of a Git repo hosted on GitHub. This is particularly useful if you want to play around with a GitHub repo but you don't have write permissions to it; you can simply fork the repo and do whatever you want with the fork as you are the owner of the fork.
0. Create a GitHub account if you don't have one yet.
1. Go to the GitHub repo you want to fork e.g., samplerepo-things
2. Click on the ![]() button on the top-right corner. In the next step, choose to fork to your own account or to another GitHub organization that you are an admin of.
button on the top-right corner. In the next step, choose to fork to your own account or to another GitHub organization that you are an admin of.
GitHub does not allow you to fork the same repo more than once to the same destination. If you want to re-fork, you need to delete the previous fork.
Tools → Git and GitHub → push: Uploading data to other repos
Tools → Git & GitHub → Pull
Can push to a remote repo
Given below is a scenario you can try in order to learn how to push commits to a remote repo hosted on GitHub:
You can push new commits in one repo to another repo which will copy the new commits onto the destination repo. Note that pushing to a repo requires you to have write-access to it. Furthermore, you can push between repos only if those repos have a shared history among them (i.e., one was created by copying the other at some point in the past).
1. Fork an existing GitHub repo (e.g., samplerepo-things) to your GitHub account.
2. Clone the fork (not the original) to your computer.
3. Commit some changes in your local repo.
4. Push the new commits to your fork on GitHub
Click the Push button on the main menu, ensure the settings are as follows in the next dialog, and click the Push button on the dialog.
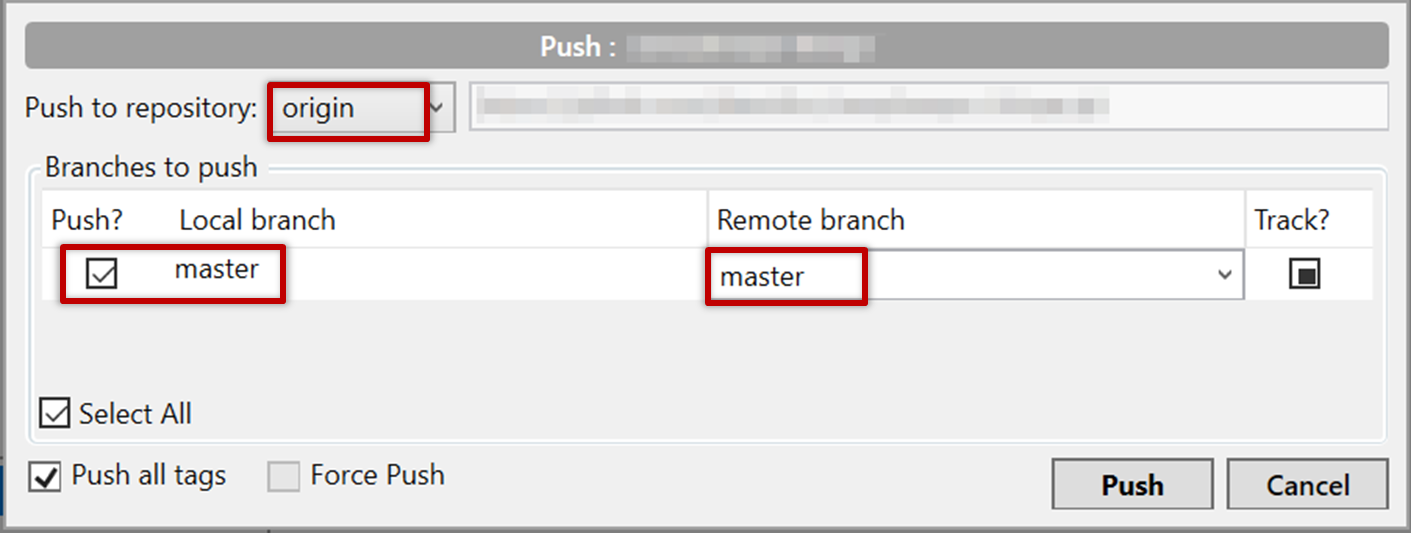
Tags are not included in a normal push. Remember to tick Push all tags when pushing to the remote repo if you want them to be pushed to the repo.
Use the command git push origin master. Enter your Github username and password when prompted.
Tags are not included in a normal push. To push a tag, use this command: git push origin <tag_name> e.g. git push origin v1.0
You can push to repos other than the one you cloned from, as long as the target repo and your repo have a shared history.
- Add the GitHub repo URL as a remote, if you haven't done so already.
- Push to the target repo.
Working with multiple remotes
When you clone a repo, Git automatically adds a remote repo named origin to your repo configuration. As you know, you can pull commits from that repo. As you know, a Git repo can work with remote repos other than the one it was cloned from.
A repo can work with any number of other repositories as long as they have a shared history e.g., repo1 can pull from (or push to) repo2 and repo3 if they have a shared history between them.
To communicate with another remote repo, you can first add it as a remote of your repo. Here is an example scenario you can follow to learn how to pull from another repo:
-
Open the local repo in SourceTree. Suggested: Use your local clone of the
samplerepo-thingsrepo. -
Choose
Repository→Repository Settingsmenu option. -
Add a new remote to the repo with the following values.
Remote name: the name you want to assign to the remote repo e.g.,upstream1URL/path: the URL of your repo (ending in.git) that. Suggested:https://github.com/se-edu/samplerepo-things-2.git(samplerepo-things-2is another repo that has a shared history withsamplerepo-things)Username: your GitHub username
-
Now, you can pull from the added repo as you did before but choose the remote name of the repo you want to pull from (instead of
origin):
If the
Remote branch to pulldropdown is empty, click theRefreshbutton on its right. -
If the pull from the
samplerepo-things-2was successful, you should have received one more commit into your local repo.
-
Navigate to the folder containing the local repo.
-
Set the new remote repo as a remote of the local repo.
command:git remote add {remote_name} {remote_repo_url}
e.g.,git remote add upstream1 https://github.com/johndoe/foobar.git -
Now you can pull from the new remote.
e.g.,git pull upstream1 master
Push your repo to the new remote the usual way, but select the name of target remote instead of origin and remember to select the Track checkbox.
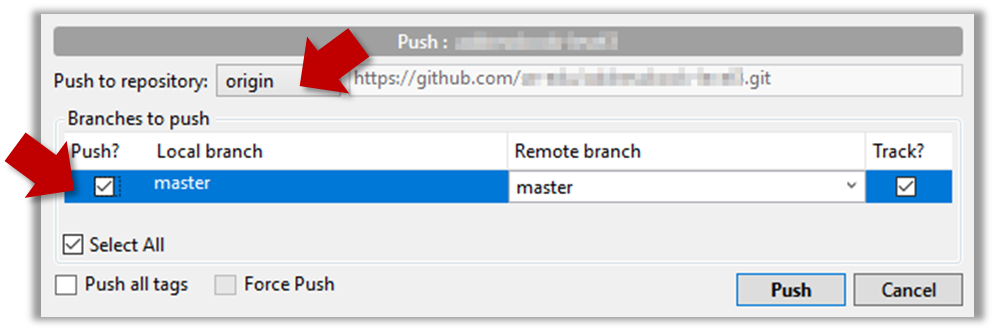
Push to the new remote the usual way e.g., git push upstream1 master (assuming you gave the name upstream1 to the remote).
You can even push an entire local repository to GitHub, to form an entirely new remote repository. For example, you created a local repo and worked with it for a while but now you want to upload it onto GitHub (as a backup or to share it with others). The steps are given below.
1. Create an empty remote repo on GitHub.
-
Login to your GitHub account and choose to create a new Repo.
-
In the next screen, provide a name for your repo but keep the
Initialize this repo ...tick box unchecked.
-
Note the URL of the repo. It will be of the form
https://github.com/{your_user_name}/{repo_name}.git.
e.g.,https://github.com/johndoe/foobar.git(note the.gitat the end)
2. Add the GitHub repo URL as a remote of the local repo. You can give it the name origin (or any other name).
Working with multiple remotes
When you clone a repo, Git automatically adds a remote repo named origin to your repo configuration. As you know, you can pull commits from that repo. As you know, a Git repo can work with remote repos other than the one it was cloned from.
A repo can work with any number of other repositories as long as they have a shared history e.g., repo1 can pull from (or push to) repo2 and repo3 if they have a shared history between them.
To communicate with another remote repo, you can first add it as a remote of your repo. Here is an example scenario you can follow to learn how to pull from another repo:
-
Open the local repo in SourceTree. Suggested: Use your local clone of the
samplerepo-thingsrepo. -
Choose
Repository→Repository Settingsmenu option. -
Add a new remote to the repo with the following values.
Remote name: the name you want to assign to the remote repo e.g.,upstream1URL/path: the URL of your repo (ending in.git) that. Suggested:https://github.com/se-edu/samplerepo-things-2.git(samplerepo-things-2is another repo that has a shared history withsamplerepo-things)Username: your GitHub username
-
Now, you can pull from the added repo as you did before but choose the remote name of the repo you want to pull from (instead of
origin):
If the
Remote branch to pulldropdown is empty, click theRefreshbutton on its right. -
If the pull from the
samplerepo-things-2was successful, you should have received one more commit into your local repo.
-
Navigate to the folder containing the local repo.
-
Set the new remote repo as a remote of the local repo.
command:git remote add {remote_name} {remote_repo_url}
e.g.,git remote add upstream1 https://github.com/johndoe/foobar.git -
Now you can pull from the new remote.
e.g.,git pull upstream1 master
3. Push the repo to the remote.
Push each branch to the new remote the usual way but use the -u flag to inform Git that you wish to i.e., remember which branch in the remote repo corresponds to which branch in the local repotrack the branch.
e.g., git push -u origin master
Project Management → Revision Control → Using history
Can explain using history
RCS tools store the history of the working directory as a series of commits. This means you should commit after each change that you want the RCS to 'remember'.
Each commit in a repo is a recorded point in the history of the project that is uniquely identified by an auto-generated hash e.g. a16043703f28e5b3dab95915f5c5e5bf4fdc5fc1.
You can tag a specific commit with a more easily identifiable name e.g. v1.0.2.
To see what changed between two points of the history, you can ask the RCS tool to diff the two commits in concern.
To restore the state of the working directory at a point in the past, you can checkout the commit in concern. i.e., you can traverse the history of the working directory simply by checking out the commits you are interested in.
RCS: Revision control software are the software tools that automate the process of Revision Control i.e. managing revisions of software artifacts.
Tools → Git and GitHub → tag: Naming commits
Project Management → Revision Control → Saving History
Can tag commits using Git
Each Git commit is uniquely identified by a hash e.g., d670460b4b4aece5915caf5c68d12f560a9fe3e4. As you can imagine, using such an identifier is not very convenient for our day-to-day use. As a solution, Git allows adding a more human-readable tag to a commit e.g., v1.0-beta.
Here's how you can tag a commit in a local repo (e.g. in the samplerepo-things repo):
Right-click on the commit (in the graphical revision graph) you want to tag and choose Tag….
Specify the tag name e.g. v1.0 and click Add Tag.
The added tag will appear in the revision graph view.
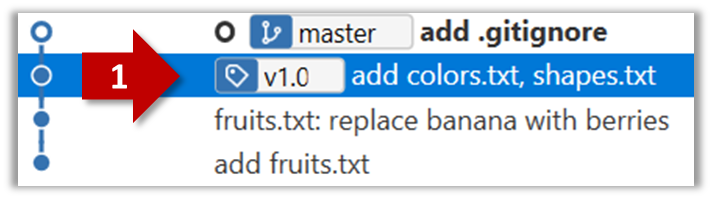
To add a tag to the current commit as v1.0,
git tag –a v1.0
To view tags
git tag
To learn how to add a tag to a past commit, go to the ‘Git Basics – Tagging’ page of the git-scm book and refer the ‘Tagging Later’ section.
Remember to push tags to the repo. A normal push does not include tags.
# push a specific tag
git push origin v1.0b
# push all tags
git push origin --tags
After adding a tag to a commit, you can use the tag to refer to that commit, as an alternative to using the hash.
Tools → Git and GitHub → diff: Comparing revisions
Project Management → Revision Control → Using History
Can compare git revisions
Git can show you what changed in each commit.
To see which files changed in a commit, click on the commit. To see what changed in a specific file in that commit, click on the file name.
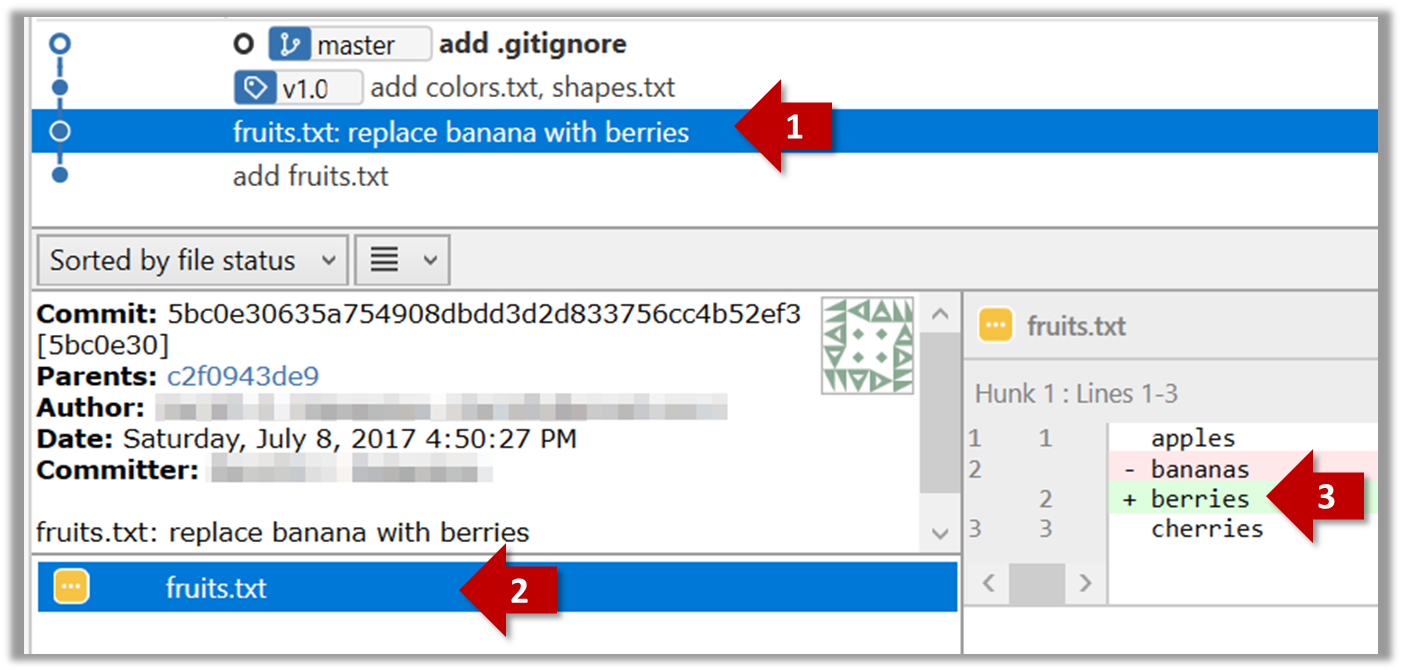
git show < part-of-commit-hash >
Example:
git show 251b4cf
commit 5bc0e30635a754908dbdd3d2d833756cc4b52ef3
Author: … < … >
Date: Sat Jul 8 16:50:27 2017 +0800
fruits.txt: replace banana with berries
diff --git a/fruits.txt b/fruits.txt
index 15b57f7..17f4528 100644
--- a/fruits.txt
+++ b/fruits.txt
@@ -1,3 +1,3 @@
apples
-bananas
+berries
cherries
Git can also show you the difference between two points in the history of the repo.
Select the two points you want to compare using Ctrl+Click. The differences between the two selected versions will show up in the bottom half of SourceTree, as shown in the screenshot below.
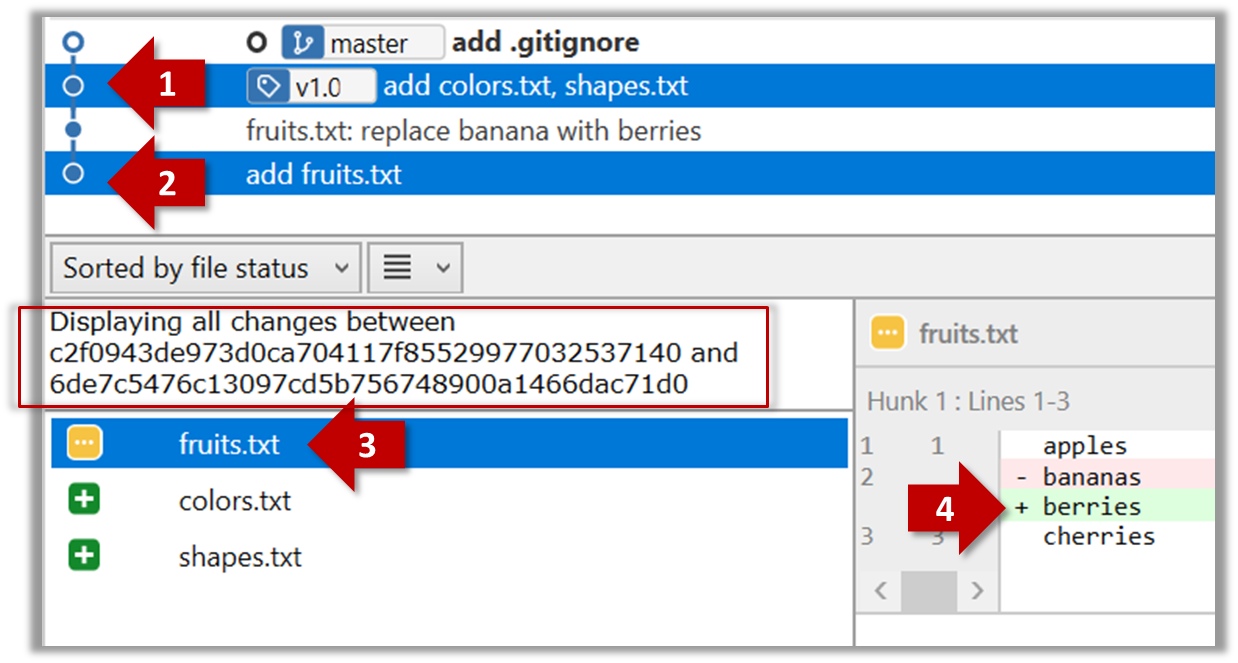
The same method can be used to compare the current state of the working directory (which might have uncommitted changes) to a point in the history.
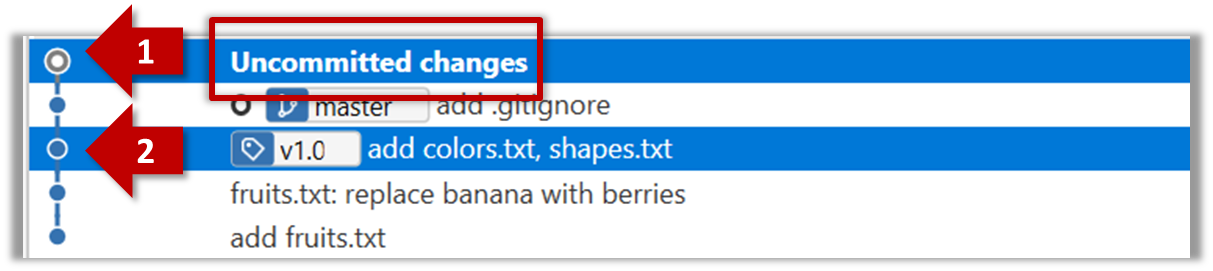
The diff command can be used to view the differences between two points of the history.
git diff: shows the changes (uncommitted) since the last commit.git diff 0023cdd..fcd6199: shows the changes between the points indicated by commit hashes.
Note that when using a commit hash in a Git command, you can use only the first few characters (e.g., first 7-10 chars) as that's usually enough for Git to locate the commit.git diff v1.0..HEAD: shows changes that happened from the commit tagged asv1.0to the most recent commit.
Resources
Tools → Git and GitHub → checkout: Retrieving a specific revision
Project Management → Revision Control → Using History
Can load a specific version of a Git repo
Git can load a specific version of the history to the working directory. Note that if you have uncommitted changes in the working directory, you need to stash them first to prevent them from being overwritten.
Can use Git to stash files
You can use Git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from Atlassian
Follow this article from SourceTree creators. Note that the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Double-click the commit you want to load to the working directory, or right-click on that commit and choose Checkout....
Click OK to the warning about ‘detached HEAD’ (similar to below).
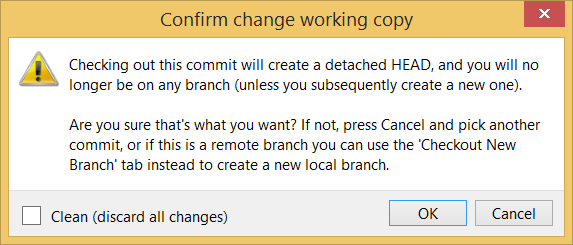
The specified version is now loaded to the working folder, as indicated by the HEAD label. HEAD is a reference to the currently checked out commit.
If you checkout a commit that comes before the commit in which you added the .gitignore file, Git will now show ignored files as ‘unstaged modifications’ because at that stage Git hasn’t been told to ignore those files.
To go back to the latest commit, double-click it.
Use the checkout <commit-identifier> command to change the working directory to the state it was in at a specific past commit.
git checkout v1.0: loads the state as at commit taggedv1.0git checkout 0023cdd: loads the state as at commit with the hash0023cddgit checkout HEAD~2: loads the state that is 2 commits behind the most recent commit
For now, you can ignore the warning about ‘detached HEAD’.
Tools → Git and GitHub → stash: Shelving changes temporarily
Can use Git to stash files
You can use Git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from Atlassian
Follow this article from SourceTree creators. Note that the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Implementation → IDEs → What
Can explain IDEs
Professional software engineers often write code using Integrated Development Environments (IDEs). IDEs support most development-related work within the same tool (hence, the term integrated).
An IDE generally consists of:
- A source code editor that includes features such as syntax coloring, auto-completion, easy code navigation, error highlighting, and code-snippet generation.
- A compiler and/or an interpreter (together with other build automation support) that facilitates the compilation/linking/running/deployment of a program.
- A debugger that allows the developer to execute the program one step at a time to observe the run-time behavior in order to locate bugs.
- Other tools that aid various aspects of coding e.g. support for automated testing, drag-and-drop construction of UI components, version management support, simulation of the target runtime platform, and modeling support.
Examples of popular IDEs:
- Java: Eclipse, Intellij IDEA, NetBeans
- C#, C++: Visual Studio
- Swift: XCode
- Python: PyCharm
Some web-based IDEs have appeared in recent times too e.g., Amazon's Cloud9 IDE.
Some experienced developers, in particular those with a UNIX background, prefer lightweight yet powerful text editors with scripting capabilities (e.g. Emacs) over heavier IDEs.
Exercises
Which of these are features available in IDEs?
- a. Compiling
- b. Syntax error highlighting
- c. Debugging
- d. Code navigation e.g., to navigate from a method call to the method implementation
- e. Simulation e.g., run a mobile app in a simulator
- f. Code analysis e.g. to find unreachable code
- g. Reverse engineering design/documentation e.g. generate diagrams from code
- h. Visual programming e.g. write programs using ‘drag and drop’ actions instead of typing code
- i. Syntax assistance e.g., show hints as you type
- j. Code generation e.g., to generate the code required by simply specifying which component/structure you want to implement
- k. Extension i.e., ability to add more functionality to the IDE using plugins
All.
Explanation: While all of these features may not be present in some IDEs, most do have these features in some form or other.
Tools → IntelliJ IDEA → Project setup
Tools → IntelliJ IDEA → Code navigation
Can navigate code effectively using IDE features
Some useful navigation shortcuts:
- Quickly locate a file by name.
- Go to the definition of a method from where it is used.
- Go back to the previous location.
- View the documentation of a method from where the method is being used, without navigating to the method itself.
- Find where a method/field is being used.
IntelliJ IDEA Code Navigation
Given below are some topics relevant to the individual project (iP) tasks due this week. These are topics you have learned in TIC2002 (as indicated by icons with the prefix), given here for your reference only. You are recommended to refresh your knowledge about them as they will be tested in the weekly quiz.