Individual Project (iP):
Team Project (tP):
Week 7 [Fri, Sep 18th] - Topics
Detailed Table of Contents
- [W7.1] SDLC Process Models: Basics
- [W7.2] Continuous Integration/Deployment
- [W7.3] Project Mgt: Workflows
-
[W7.3a] Project Management → Revision Control → Forking flow
-
[W7.3b] Tools → Git and GitHub → Forking workflow
-
[W7.3c] Project Management → Revision Control → DRCS vs CRCS
-
[W7.3d] Project Management → Revision Control → Feature branch flow : OPTIONAL
-
[W7.3e] Project Management → Revision Control → Centralized flow : OPTIONAL
Project Management → SDLC Process Models → Introduction → What
Can explain SDLC process models
Software development goes through different stages such as requirements, analysis, design, implementation and testing. These stages are collectively known as the software development life cycle (SDLC). There are several approaches, known as software development life cycle models (also called software process models), that describe different ways to go through the SDLC. Each process model prescribes a "roadmap" for the software developers to manage the development effort. The roadmap describes the aims of the development stage(s), the artifacts or outcome of each stage, as well as the workflow i.e. the relationship between stages.
Project Management → SDLC Process Models → Introduction → Sequential models
Can explain sequential process models
The sequential model, also called the waterfall model, models software development as a linear process, in which the project is seen as progressing steadily in one direction through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
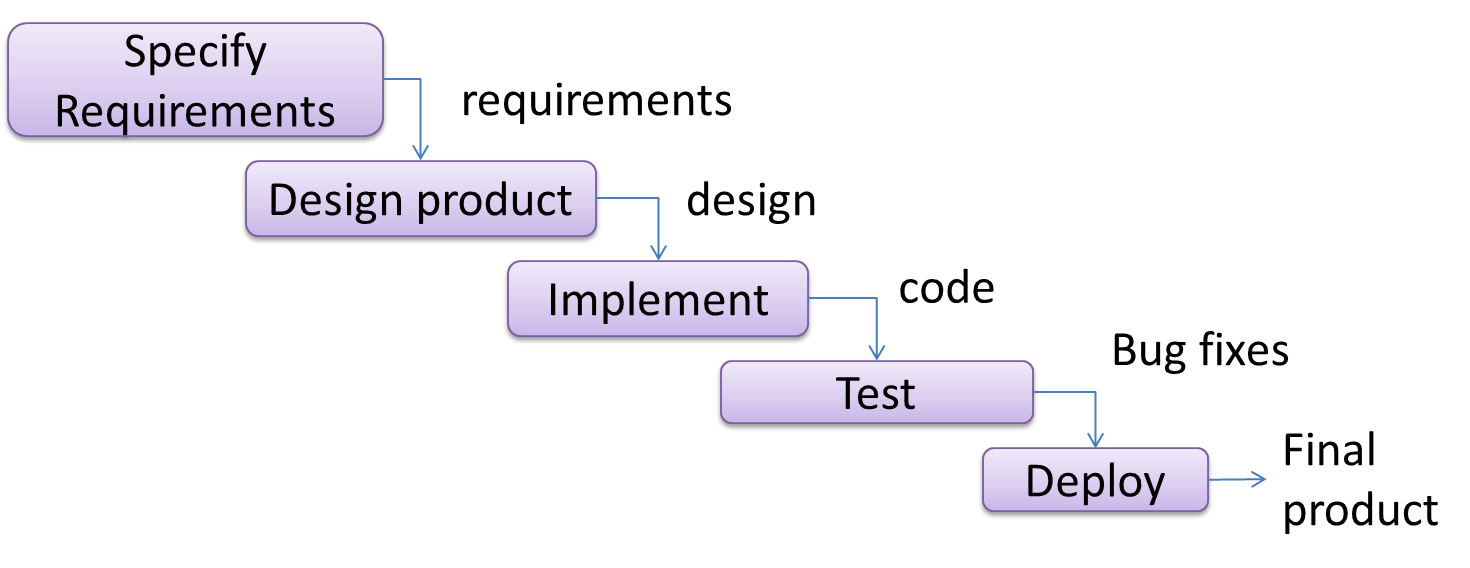
When one stage of the process is completed, it should produce some artifacts to be used in the next stage. For example, upon completion of the requirements stage, a comprehensive list of requirements is produced that will see no further modifications. A strict application of the sequential model would require each stage to be completed before starting the next.
This could be a useful model when the problem statement is well-understood and stable. In such cases, using the sequential model should result in a timely and systematic development effort, provided that all goes well. As each stage has a well-defined outcome, the progress of the project can be tracked with relative ease.
The major problem with this model is that the requirements of a real-world project are rarely well-understood at the beginning and keep changing over time. One reason for this is that users are generally not aware of how a software application can be used without prior experience in using a similar application.
Project Management → SDLC Process Models → Introduction → Iterative models
Can explain iterative process models
The iterative model (sometimes called iterative and incremental) advocates having several iterations of SDLC. Each of the iterations could potentially go through all the development stages, from requirements gathering to testing & deployment. Roughly, it appears to be similar to several cycles of the sequential model.
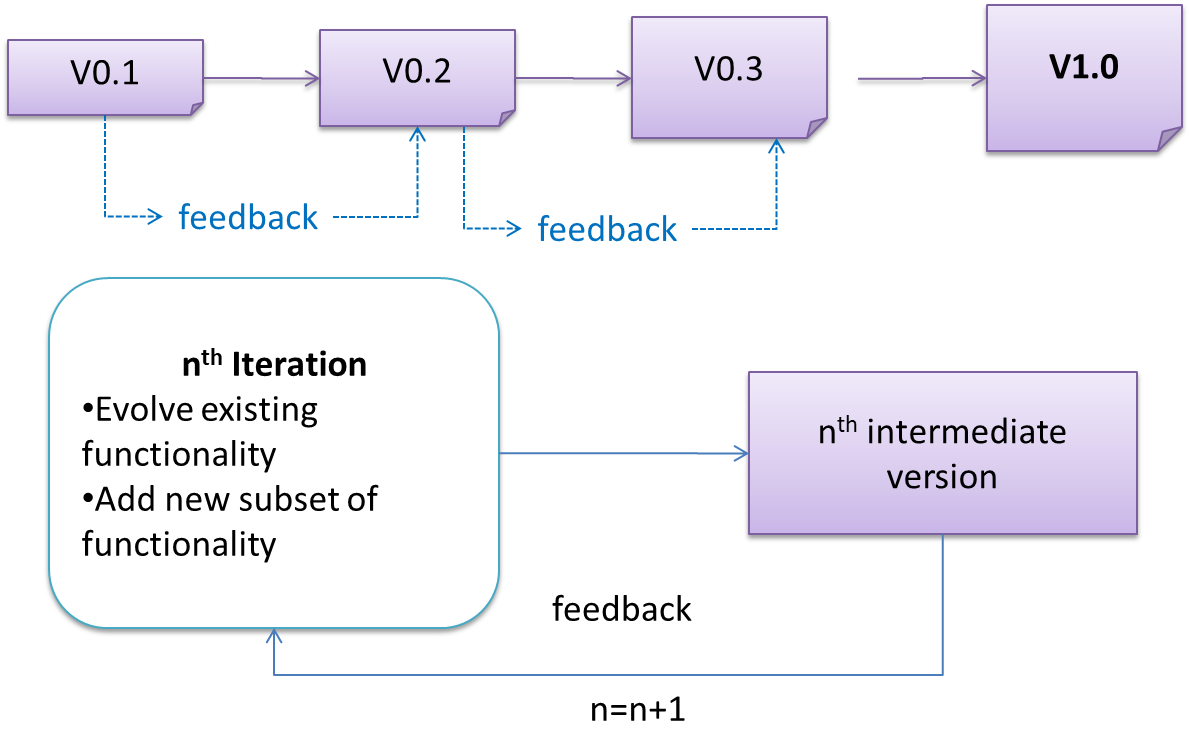
In this model, each of the iterations produces a new version of the product. Feedback on the new version can then be fed to the next iteration. Taking the Minesweeper game as an example, the iterative model will deliver a fully playable version from the early iterations. However, the first iteration will have primitive functionality, for example, a clumsy text based UI, fixed board size, limited randomization, etc. These functionalities will then be improved in later releases.
The iterative model can take a breadth-first or a depth-first approach to iteration planning.
- breadth-first: an iteration evolves all major components in parallel e.g., add a new feature fully, or enhance an existing feature.
- depth-first: an iteration focuses on fleshing out only some components e.g., update the backend to support a new feature that will be added in a future iteration.
Most projects use a mixture of breadth-first and depth-first iterations i.e., an iteration can contain some breadth-first work as well as some depth-first work.
Implementation → Integration → Introduction → What
Can explain integration
Combining parts of a software product to form a whole is called integration. It is also one of the most troublesome tasks and it rarely goes smoothly.
Implementation → Integration → Build Automation → What
Can explain build automation tools
Build automation tools automate the steps of the build process, usually by means of build scripts.
In a non-trivial project, building a product from its source code can be a complex multi-step process. For example, it can include steps such as: pull code from the revision control system, compile, link, run automated tests, automatically update release documents (e.g. build number), package into a distributable, push to repo, deploy to a server, delete temporary files created during building/testing, email developers of the new build, and so on. Furthermore, this build process can be done ‘on demand’, it can be scheduled (e.g. every day at midnight) or it can be triggered by various events (e.g. triggered by a code push to the revision control system).
Some of these build steps such as compiling, linking and packaging, are already automated in most modern IDEs. For example, several steps happen automatically when the ‘build’ button of the IDE is clicked. Some IDEs even allow customization of this build process to some extent.
However, most big projects use specialized build tools to automate complex build processes.
Some popular build tools relevant to Java developers: Gradle, Maven, Apache Ant, GNU Make
Some other build tools: Grunt (JavaScript), Rake (Ruby)
Some build tools also serve as dependency management tools. Modern software projects often depend on third party libraries that evolve constantly. That means developers need to download the correct version of the required libraries and update them regularly. Therefore, dependency management is an important part of build automation. Dependency management tools can automate that aspect of a project.
Maven and Gradle, in addition to managing the build process, can play the role of dependency management tools too.
Resources
- Getting Started with Gradle -- documentation from Gradle
- Gradle Tutorial -- from tutorialspoint.com
Working With Gradle in Intellij IDEA (6 minutes)
Exercises
Gradle is a tool for ...
Gradle is used for,
- a. better revision control
- b. build automation
- c. UML diagramming
- d. project collaboration
(b)
Implementation → Integration → Build Automation → Continuous integration and continuous deployment
Can explain continuous integration and continuous deployment
An extreme application of build automation is called continuous integration (CI) in which integration, building, and testing happens automatically after each code change.
A natural extension of CI is Continuous Deployment (CD) where the changes are not only integrated continuously, but also deployed to end-users at the same time.
Some examples of CI/CD tools: Travis, Jenkins, Appveyor, CircleCI, GitHub Actions
Project Management → Revision Control → Forking flow
Can explain forking workflow
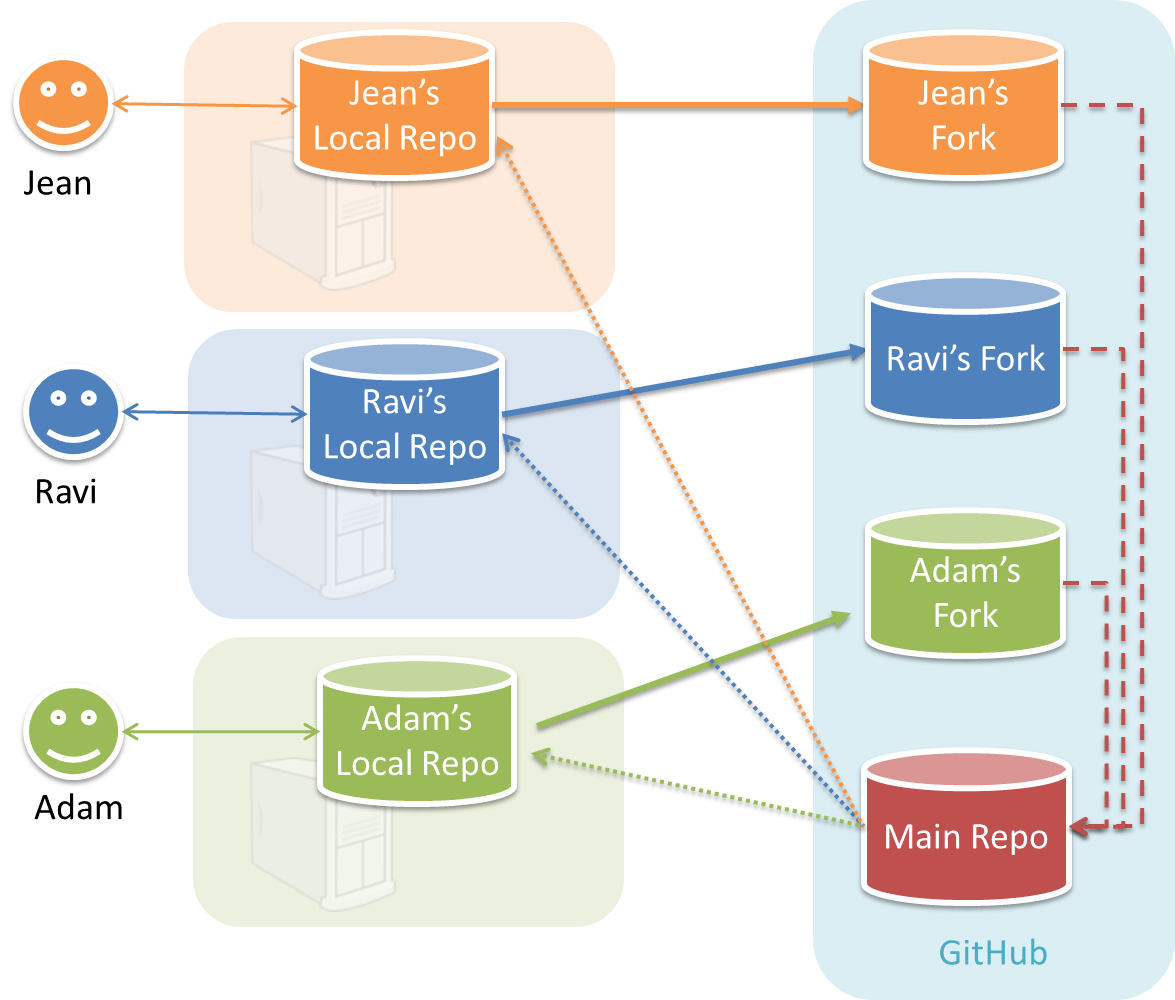
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo and create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
Common mistake: Doing the proposed changes in themasterbranch -- if Jean does that, she will not be able to have more than one PR open at any time because any changes to themasterbranch will be reflected in all open PRs. - Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork.
Possible mistake: Creating another 'reverse' PR from the team repo to the team member's fork to sync the member's fork with the merged code. PRs are meant to go from downstream repos to upstream repos, not in the other direction.
Resources
- A detailed explanation of the Forking Workflow - From Atlassian
Tools → Git and GitHub → Forking workflow
Revision Control → Forking Workflow
Can follow Forking Workflow
You can follow the steps in the simulation of a forking workflow given below to learn how to follow such a workflow.
This activity is best done as a team.
Step 1. One member: set up the team org and the team repo.
-
Create a GitHub organization for your team. The org name is up to you. We'll refer to this organization as team org from now on.
-
Add a team called
developersto your team org. -
Add team members to the
developersteam. -
Fork se-edu/samplerepo-workflow-practice to your team org. We'll refer to this as the team repo.
-
Add the forked repo to the
developersteam. Give write access.
Step 2. Each team member: create PRs via own fork.
-
Fork that repo from your team org to your own GitHub account.
-
Create a branch named
add-{your name}-info(e.g.add-johnTan-info) in the local repo. -
Add a file
yourName.mdinto themembersdirectory (e.g.,members/jonhTan.md) containing some info about you into that branch. -
Push that branch to your fork.
-
Create a PR from that branch to the
masterbranch of the team repo.
Step 3. For each PR: review, update, and merge.
-
[A team member (not the PR author)] Review the PR by adding comments (can be just dummy comments).
-
[PR author] Update the PR by pushing more commits to it, to simulate updating the PR based on review comments.
-
[Another team member] Approve and merge the PR using the GitHub interface.
-
[All members] Sync your local repo (and your fork) with upstream repo. In this case, your upstream repo is the repo in your team org.
Step 4. Create conflicting PRs.
-
[One member]: Update README: In the
masterbranch, remove John Doe and Jane Doe from theREADME.md, commit, and push to the main repo. -
[Each team member] Create a PR to add yourself under the
Team Memberssection in theREADME.md. Use a new branch for the PR e.g.,add-johnTan-name.
Step 5. Merge conflicting PRs one at a time. Before merging a PR, you’ll have to resolve conflicts.
-
[Optional] A member can inform the PR author (by posting a comment) that there is a conflict in the PR.
-
[PR author] Resolve the conflict locally:
- Pull the
masterbranch from the repo in your team org. - Merge the pulled
masterbranch to your PR branch. - Resolve the merge conflict that crops up during the merge.
- Push the updated PR branch to your fork.
- Pull the
-
[Another member or the PR author]: Merge the de-conflicted PR: When GitHub does not indicate a conflict anymore, you can go ahead and merge the PR.
Project Management → Revision Control → DRCS vs CRCS
Can explain DRCS vs CRCS
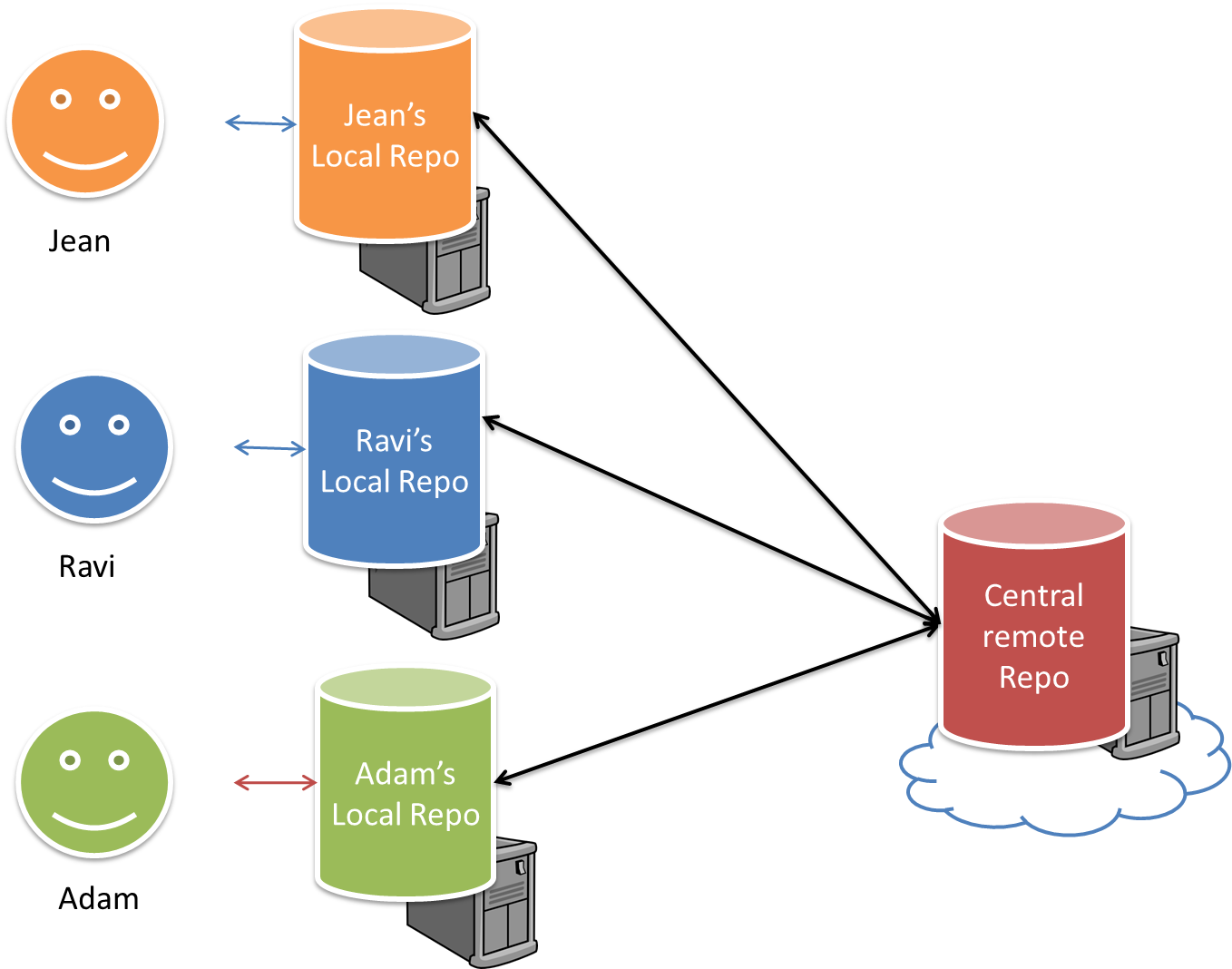
RCS can be done in two ways: the centralized way and the distributed way.
Centralized RCS (CRCS for short) uses a central remote repo that is shared by the team. Team members download (‘pull’) and upload (‘push’) changes between their own local repositories and the central repository. Older RCS tools such as CVS and SVN support only this model. Note that these older RCS do not support the notion of a local repo either. Instead, they force users to do all the versioning with the remote repo.
The centralized RCS approach without any local repos (e.g., CVS, SVN)
Distributed RCS (DRCS for short, also known as Decentralized RCS) allows multiple remote repos and pulling and pushing can be done among them in arbitrary ways. The workflow can vary differently from team to team. For example, every team member can have his/her own remote repository in addition to their own local repository, as shown in the diagram below. Git and Mercurial are some prominent RCS tools that support the distributed approach.
The decentralized RCS approach
Project Management → Revision Control → Feature branch flow
Revision Control → Forking Workflow
Can explain feature branch flow
Feature branch workflow is similar to forking workflow except there are no forks. Everyone is pushing/pulling from the same remote repo. The phrase feature branch is used because each new feature (or bug fix, or any other modification) is done in a separate branch and merged to the master branch when ready.
Resources
- A detailed explanation of the Feature Branch Workflow - From Atlassian
Project Management → Revision Control → Centralized flow
Revision Control → Feature Branch Workflow
Can explain centralized flow
The centralized workflow is similar to the feature branch workflow except all changes are done in the master branch.
Resources
- A detailed explanation of the Centralized Workflow - From Atlassian