- Start the next iteration
- Update the DG: user stories, glossary, NFRs
- Ensure the code RepoSense-compatible
1 Start the next iteration
In the final iteration (i.e., the one after this), you will be doing a lot of additional things e.g., adding documentation. Hence, it is in your interest to finish implementing all your features you want to include in your final version (i.e., v3.0)final features in this iteration itself so that you can use the final iteration for polishing up the functionalities and adding documentation.
As you did in the previous iteration,
- Plan the next iteration (steps are given below as a reminder):
- Decide which enhancements will be added to the product in this iteration, if this is the last iteration.
- If possible, split that into two incremental versions.
- Divide the work among team members.
- Reflect the above plan in the issue tracker.
- Start implementing the features as per the plan made above.
- Track the progress using GitHub issue tracker, milestones, labels, etc.
In addition,
- Maintain the defensiveness of the code: Remember to use assertions, exceptions, and logging in your code, as well as other defensive programming measures when appropriate.
Remember to enable assertions in your IDEA run configurations and in the gradle file. - Recommend: Each PR should also update the relevant parts of documentation and tests. That way, your documentation/testing work will not pile up towards the end.
2 Update the DG: user stories, glossary, NFRs
Recommended: Divide i.e., work related to the User Guide and the Developer Guidedocumentation work among team members equally; preferably based on enhancements/features each person would be adding e.g., If you are the person planing to add a feature X, you should be the person to describe the feature X in the User Guide and in the Developer Guide.
Reason: In the final project evaluation your documentation skills will be graded based on sections of the User/Developer Guide you have written.
Admin tP: Grading → Documentation
-
Add the following to the DG, based on your project notes from the previous weeks.
Some examples of these can be found in the AB3 Developer Guide.- Target user profile, value proposition, and user stories: Update the target user profile and value proposition to match the project direction you have selected. Give a list of the user stories (and update/delete existing ones, if applicable), including priorities. This can include user stories considered but will not be included in the final product.
- Non-functional requirements: Note: Many of the given project constraints can be considered NFRs. You can add more. e.g. performance requirements, usability requirements, scalability requirements, etc.
- Glossary: Define terms that are worth recording.
Requirements → Specifying Requirements → Use Cases →
Use case: A description of a set of sequences of actions, including variants, that a system performs to yield an observable result of value to an actor.[ 📖 : uml-user-guideThe Unified Modeling Language User Guide, 2e, G Booch, J Rumbaugh, and I Jacobson ]
Actor: An actor (in a use case) is a role played by a user. An actor can be a human or another system. Actors are not part of the system; they reside outside the system.
A use case describes an interaction between the user and the system for a specific functionality of the system.
Example 1: 'transfer money' use case for an online banking system
System: Online Banking System (OBS) Use case: UC23 - Transfer Money Actor: User MSS: 1. User chooses to transfer money. 2. OBS requests for details of the transfer. 3. User enters the requested details. 4. OBS requests for confirmation. 5. User confirms. 6. OBS transfers the money and displays the new account balance. Use case ends.
Extensions:
3a. OBS detects an error in the entered data.
3a1. OBS requests for the correct data.
3a2. User enters new data.
Steps 3a1-3a2 are repeated until the data entered are correct.
Use case resumes from step 4.
3b. User requests to effect the transfer in a future date.
3b1. OBS requests for confirmation.
3b2. User confirms future transfer.
Use case ends.
*a. At any time, User chooses to cancel the transfer.
*a1. OBS requests to confirm the cancellation.
*a2. User confirms the cancellation.
Use case ends.
Example 2: 'upload file' use case of an LMS
- System: A Learning Management System (LMS)
- Actor: Student
- Use Case: Upload file
- Student requests to upload file
- LMS requests for the file location
- Student specifies the file location
- LMS uploads the file
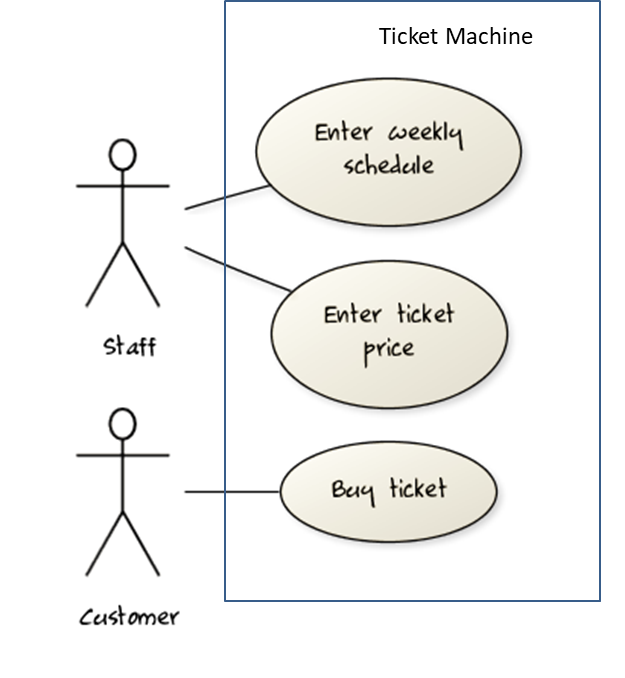
UML includes a diagram type called use case diagrams that can illustrate use cases of a system visually, providing a visual ‘table of contents’ of the use cases of a system.
In the example on the right, note how use cases are shown as ovals and user roles relevant to each use case are shown as stick figures connected to the corresponding ovals.
Unified Modeling Language (UML) is a graphical notation to describe various aspects of a software system. UML is the brainchild of three software modeling specialists James Rumbaugh, Grady Booch and Ivar Jacobson (also known as the Three Amigos). Each of them had developed their own notation for modeling software systems before joining forces to create a unified modeling language (hence, the term ‘Unified’ in UML). UML is currently the de facto modeling notation used in the software industry.
Use cases capture the functional requirements of a system.
Requirements → Requirements →
Requirements can be divided into two in the following way:
- Functional requirements specify what the system should do.
- Non-functional requirements specify the constraints under which the system is developed and operated.
Some examples of non-functional requirement categories:
- Data requirements e.g. size, how often do data changevolatility, saving data permanentlypersistency etc.,
- Environment requirements e.g. technical environment in which the system would operate in or needs to be compatible with.
- Accessibility, Capacity, Compliance with regulations, Documentation, Disaster recovery, Efficiency, Extensibility, Fault tolerance, Interoperability, Maintainability, Privacy, Portability, Quality, Reliability, Response time, Robustness, Scalability, Security, Stability, Testability, and more ...
Some concrete examples of NFRs
- Business/domain rules: e.g. the size of the minefield cannot be smaller than five.
- Constraints: e.g. the system should be backward compatible with data produced by earlier versions of the system; system testers are available only during the last month of the project; the total project cost should not exceed $1.5 million.
- Technical requirements: e.g. the system should work on both 32-bit and 64-bit environments.
- Performance requirements: e.g. the system should respond within two seconds.
- Quality requirements: e.g. the system should be usable by a novice who has never carried out an online purchase.
- Process requirements: e.g. the project is expected to adhere to a schedule that delivers a feature set every one month.
- Notes about project scope: e.g. the product is not required to handle the printing of reports.
- Any other noteworthy points: e.g. the game should not use images deemed offensive to those injured in real mine clearing activities.
You may have to spend an extra effort in digging NFRs out as early as possible because,
- NFRs are easier to miss e.g., stakeholders tend to think of functional requirements first
- sometimes NFRs are critical to the success of the software. E.g. A web application that is too slow or that has low security is unlikely to succeed even if it has all the right functionality.
Exercises
TEAMMATES NFRs
Given below are some requirements of TEAMMATES (an online peer evaluation system for education). Which one of these are non-functional requirements?
- a. The response to any use action should become visible within 5 seconds.
- b. The application admin should be able to view a log of user activities.
- c. The source code should be open source.
- d. A course should be able to have up to 2000 students.
- e. As a student user, I can view details of my team members so that I can know who they are.
- f. The user interface should be intuitive enough for users who are not IT-savvy.
- g. The product is offered as a free online service.
(a)(c)(d)(f)(g)
Explanation: (b) are (e) are functions available for a specific user types. Therefore, they are functional requirements. (a), (c), (d), (f) and (g) are either constraints on functionality or constraints on how the project is done, both of which are considered non-functional requirements.
Requirements → Specifying Requirements → Glossary →
Glossary: A glossary serves to ensure that all stakeholders have a common understanding of the noteworthy terms, abbreviations, acronyms etc.
Here is a partial glossary from a variant of the Snakes and Ladders game:
- Conditional square: A square that specifies a specific face value which a player has to throw before his/her piece can leave the square.
- Normal square: a normal square does not have any conditions, snakes, or ladders in it.
Requirements → Specifying Requirements → User Stories →
User story: User stories are short, simple descriptions of a feature told from the perspective of the person who desires the new capability, usually a user or customer of the system. [Mike Cohn]
A common format for writing user stories is:
User story format: As a {user type/role} I can {function} so that {benefit}
Examples (from a Learning Management System):
- As a student, I can download files uploaded by lecturers, so that I can get my own copy of the files
- As a lecturer, I can create discussion forums, so that students can discuss things online
- As a tutor, I can print attendance sheets, so that I can take attendance during the class
You can write user stories on index cards or sticky notes, and arrange them on walls or tables, to facilitate planning and discussion. Alternatively, you can use a software (e.g., GitHub Project Boards, Trello, Google Docs, ...) to manage user stories digitally.
User stories in use
With sticky notes

With paper

[credit: https://www.flickr.com/photos/jakuza/with/2726048607/]
With software
[credit: https://commons.wikimedia.org/wiki/File:User_Story_Map_in_Action.png]
{kind=link}
Exercises
Which of these are true about user stories?
- a. They are based on stories users tell about similar systems
- b. They are written from the user/customer perspective
- c. They are always written in some physical medium such as index cards or sticky notes
- a. Reason: Despite the name, user stories are not related to 'stories' about the software.
- b.
- c. Reason: It is possible to use software to record user stories. When the team members are not co-located this may be the only option.
What's wrong with this user story?
Critique the following user story taken from a software project to build an e-commerce website.
As a developer, I want to use Python to implement the software, so that we can reuse existing Python modules.
Refer to the definition of a user story.
User story: User stories are short, simple descriptions of a feature told from the perspective of the person who desires the new capability, usually a user or customer of the system. [Mike Cohn]
This user story is not written from the perspective of the user/customer.
Extract user stories from customer statement
Bill wants you to build a Human Resource Management (HRM) system. He mentions that the system will help employees to view their own The number of leave days not yet takenleave balance. What are the user stories you can extract from that statement?
Remember to follow the correct format when writing user stories.
User story format: As a {user type/role} I can {function} so that {benefit}
As an employee, I can view my leave balance, so that I can know how many leave days I have left.
Note: the {benefit} part may vary as it is not specifically mentioned in the question.
3 Ensure the code RepoSense-compatible
-
Ensure your code is i.e., RepoSense can detect your code as yoursRepoSense-compatible and the code it attributes to you is indeed the code written by you, as explained below:
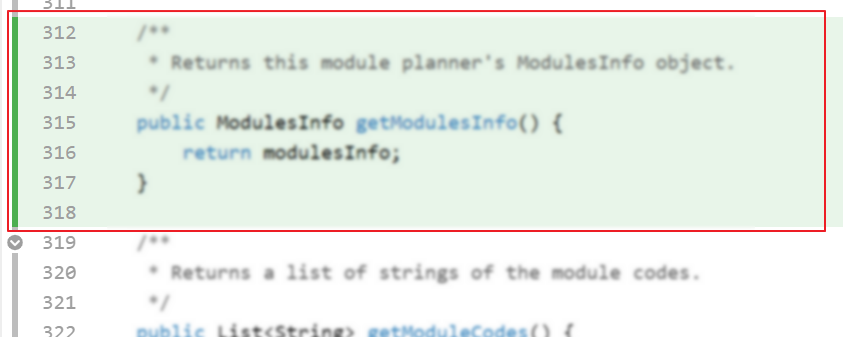
- Go to the tp Code Dashboard. Click on the
</>icon against your name and verify that the lines attributed to you (i.e., lines marked as green) reflects your code contribution correctly. This is important because some aspects of your project grade (e.g., code quality) will be graded based on those lines.
- More info on how to make the code RepoSense compatible:
- Go to the tp Code Dashboard. Click on the
Admin Tools → RepoSense
Tool: RepoSense (for authorship tracking)
We will be using a tool called RepoSense to make it easier for you to see (and learn from) code written by others, and to help us see who wrote which part of the code.
Viewing the current status of code authorship data:
- The reports generated by the tool for the individual and team projects will be made available in the module website at some point in the semester. The feature that is most relevant to you is the Code Panel (shown on the right side of the screenshot above). It shows the code attributed to a given author.
- Click on your name to load the code attributed to you (based on Git blame/log data) onto the code panel on the right.
- If the code shown roughly matches the code you wrote, all is fine and there is nothing for you to do.
If the code does not match the actual authorship: Given below are the possible reasons for the code shown to mismatch the code you wrote.
-
Reason 1: the
Author nameof some of your commits is not known to RepoSense -- this is a result of not setting thegit.usernameproperty as instructed in our Git setup instructions.
How to check: Find theAuthor nameof your commits that are missing (you can use SourceTree or thegit logcommand for that -- it's not possible to do that using the GitHub interface though).
Check if that author name is included in the RepoSense config for the iP or the RepoSense config for the tP (whichever the applicable one)
Remedy: Send the missing author name(s) to the prof so that the RepoSense configuration can be updated accordingly. -
Reason 2: The actual authorship does not match the authorship determined by git blame/log e.g., another student touched your code after you wrote it, and Git log attributed the code to that student instead.
Remedy: You can add@@authorannotations as explained in the panel below:
Adding @@author tags to indicate authorship
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe
method 1 ...
method 2 ...
//@@author sarahkhoo
method 3 ...
//@@author johndoe
method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ...
//@@author johndoe
method 1 ...
method 2 ...
//@@author
method 3 ...
method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong -->
<textbox>
<label>...</label>
<input>...</input>
</textbox>
... -
Do not put the
//@@authorinside java header comments.
👎/**
* Returns true if ...
* @@author johndoe
*/👍
//@@author johndoe
/**
* Returns true if ...
*/
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused
method 1 ...
method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused
method 1 ...
method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the code to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
- Reason 3: Some commits should not be included in the authorship analysis e.g., you committed the code of a third party library by mistake.
Remedy: Let us know the hashes of the commits that need to be omitted from the analysis.
If none of the above works, please please post in the forum or contact us via tic4001@comp.nus.edu.sg so that we can advise you what to do.
We recommend you ensure your code is RepoSense-compatible by v2.0